당시의 질문은 단순했다. "한국어 음성을 텍스트로 바꾸는 일을 실제 업무에 붙인다면, 어떤 모델이 얼마나 잘 맞히는가?" 하지만 테스트를 시작하자 곧 더 중요한 질문이 생겼다. "잘 맞혔다"는 말을 어떤 숫자로, 어떤 정답지 기준으로, 어느 정도의 오류 허용선 안에서 말할 것인가.
당시 공개 기고문: ITDaily ComputerWorld
상황: 모델 출력보다 먼저 평가 기준이 필요했다
공개 클라우드 STT와 오픈소스 Whisper 모델은 모두 transcript를 반환하지만, 그 transcript가 같은 방식으로 틀리지는 않았다. 어떤 결과는 띄어쓰기만 달랐고, 어떤 결과는 숫자를 한글로 풀어썼고, 어떤 결과는 고유명사나 외래어에서 크게 흔들렸다. 그래서 원문과 출력문을 눈으로 읽는 것만으로는 비교가 끝나지 않았다. 같은 음성, 같은 정답지, 같은 오류 계산식이 필요했다.
이때 별도로 만든 것이 Compute STT Error Rate, 즉 Nlptutti 패키지다. 공개 레포는
computing-Korean-STT-error-rates이고,
테스트 코드에서는 nlptutti로 import해 사용했다. Nlptutti는 get_cer,
get_wer, get_crr와 키워드 패턴 유틸리티로 구성했다.
내부적으로 Levenshtein edit distance를 사용해 substitutions, deletions, insertions를 세고,
공백과 문장부호 처리 같은 한국어 STT 평가의 민감한 기준을 코드로 고정했다.
직접 만들었던 이유도 분명했다. 기존 방식처럼 reference 길이만 분모로 두면 insertion이 많은 transcript에서
CER가 1을 넘거나 원하는 0-1 범위 밖으로 튈 수 있었다. 그래서 Nlptutti는 오류항
S+D+I를 numerator로 두되, denominator를 S+D+I+C로 잡아 insertion까지 포함한
normalized error rate로 계산했다. 이 작은 정규화 항이 한국어 STT 결과를 반복 비교할 수 있게 만든
핵심이었다.
진행: 두 개의 테스트면으로 나눴다
첫 번째 테스트는 단일 화자 3,922문장 벤치마크였다. 같은 file_name과
ground_truth를 기준으로 AWS Transcribe와 Whisper base, medium, large의 transcript를 모았다.
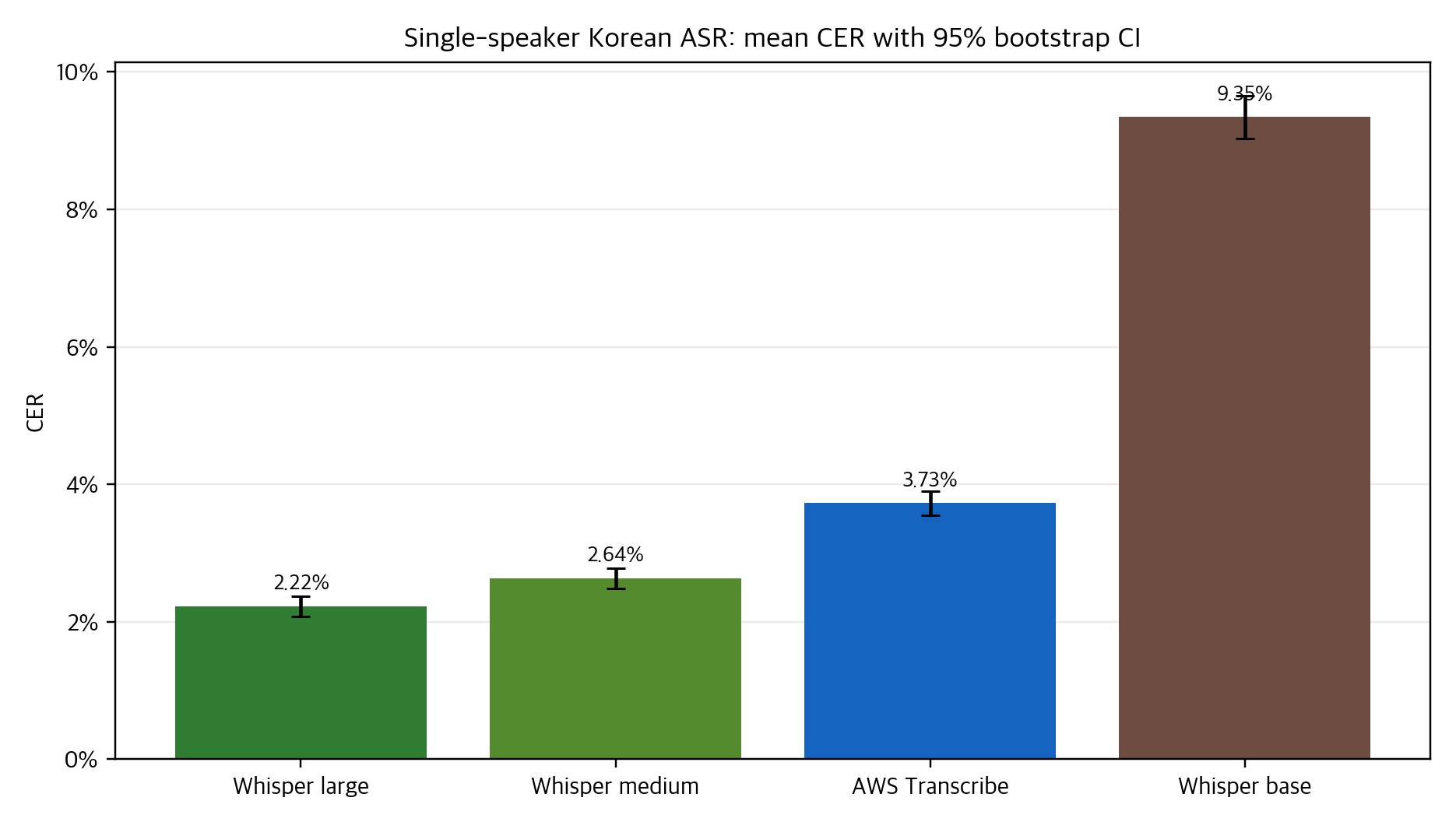
각 행에는 정답 문장, 모델 출력, CER가 남도록 했다. 이 데이터는 모델별 평균 성능뿐 아니라
문장 단위로 누가 더 자주 낮은 CER를 보였는지 비교할 수 있는 기준면이 됐다.
중심 데이터인 3,922문장은 직접 읽고 녹음한 내 음성 데이터였다. 집 안에서 비교적 조용하고 반향이 적은 서재에서 하루 50문장을 목표로 읽었다. 문장은 멀티 패턴 USB 콘덴서 마이크의 단일 지향성(cardioid) 수음 모드로 하나씩 WAV 파일로 남겼고, 누적 리딩과 녹음 시간은 거의 8시간에 가까웠다. 실험 설계부터 녹음, STT 실행, 결과 수집, metric 고정까지 약 3개월 동안 직접 리딩한 작업이었다.
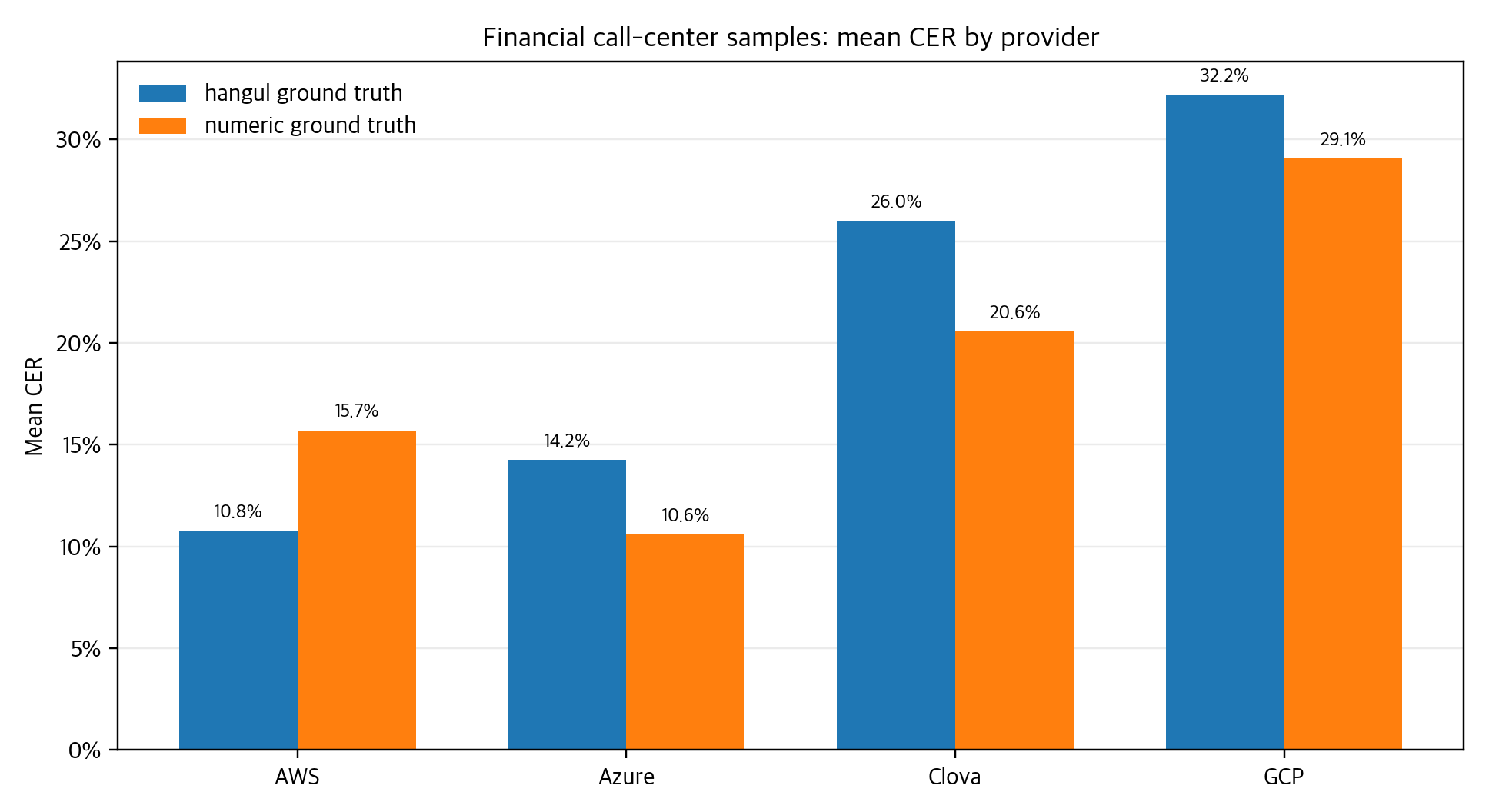
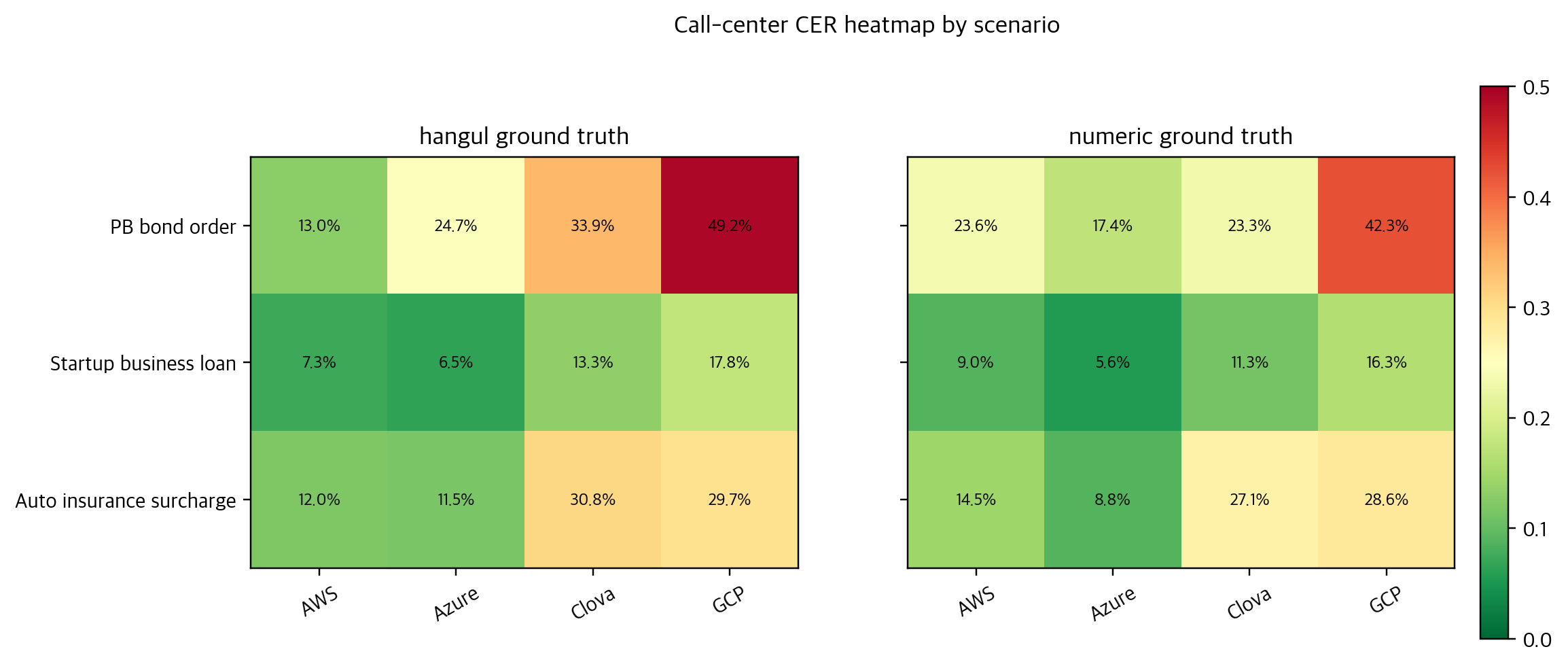
두 번째 테스트는 금융 콜센터를 가정한 3개 persona였다. PB 채권 주문, 신생기업 대출 안내, 자동차 보험료 할증 문의처럼 전화번호, 계좌번호, 금액, 날짜 같은 숫자 정보가 자주 등장하는 상담을 짧게 검증해보기 위한 간이 테스트였다. 팀원 몇 명과 30분 정도 미팅하고 녹음했고, 미팅룸 공간을 고려해 개인 비용으로 준비한 멀티 패턴 USB 콘덴서 마이크를 양방향(bidirectional) 수음 모드로 두어 1:1 대화의 양쪽 음성을 균형 있게 담아보려 했다. 표본이 작기 때문에 provider 순위를 내기 위한 용도는 아니었다. 대신 같은 상담이 한글 정답지와 숫자 정답지에서 얼마나 다르게 평가되는지, 숫자 표기 정책이 CER를 어떻게 흔드는지 보기 위한 case analysis였다.
액션: 평균 하나 대신 운영 가능한 메트릭을 골랐다
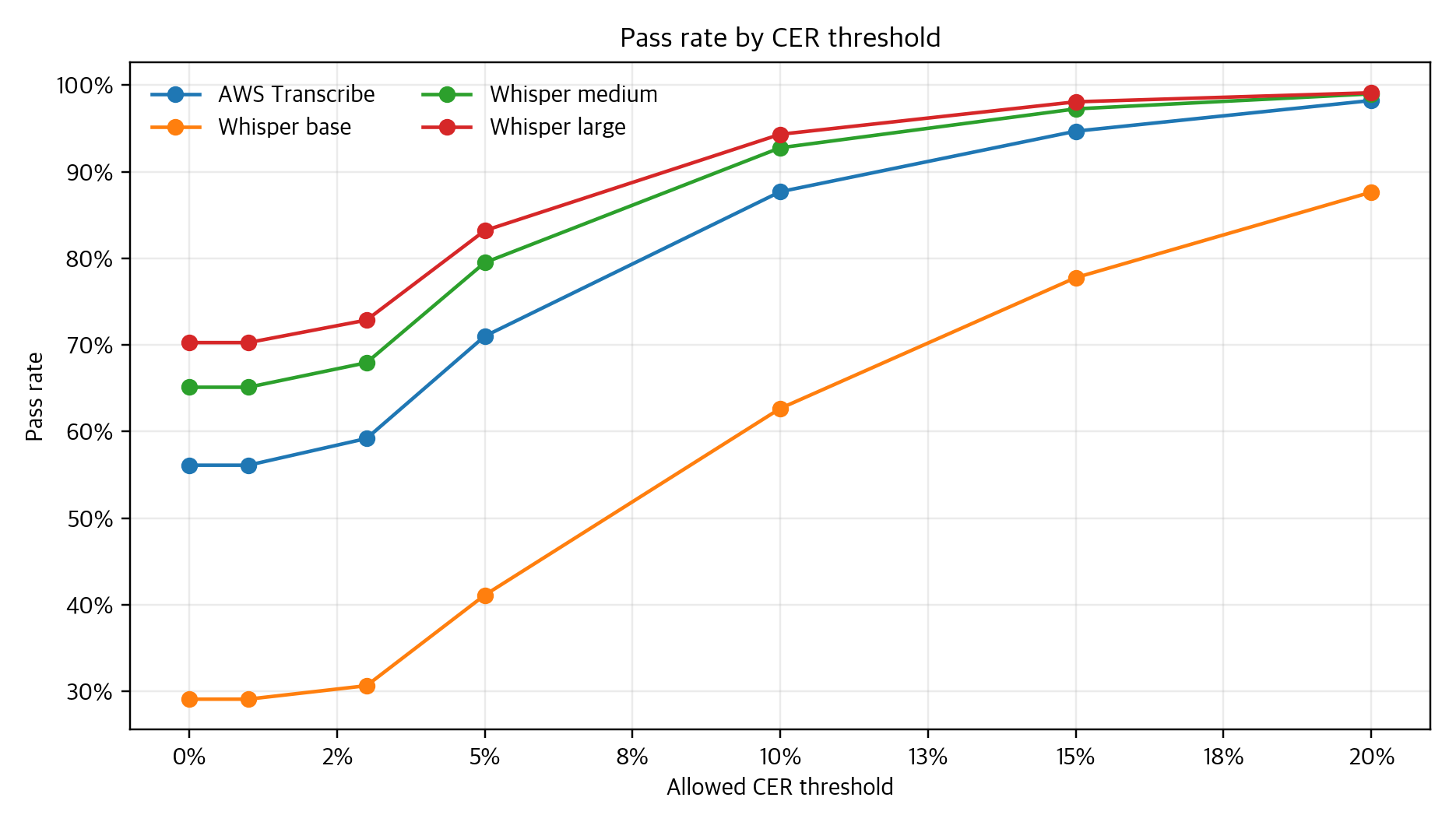
결과를 읽을 때는 평균 CER만 보지 않았다. 평균은 전체 경향을 주지만, 실제 workflow에서는 "자동 통과시킬 수 있는 문장이 몇 개인가", "검수 queue로 보내야 할 tail이 얼마나 남는가"가 더 직접적이다. 그래서 완전 인식률, 5% 이하 pass rate, 10% 초과 tail risk, paired delta, worst/disagreement examples, scenario heatmap을 함께 만들었다.
가장 번거로웠던 부분은 모델을 실행하는 것보다 결과를 같은 좌표에 올리는 일이었다. provider마다 JSON, TXT, CSV 형태가 달랐고, 한국어에서는 띄어쓰기와 문장부호, 숫자 표기 하나가 CER를 크게 바꿨다. 특히 보험료 할증 문의처럼 번호, 금액, 날짜가 섞인 상담에서는 "의미는 비슷하지만 문자는 다른" 결과가 반복됐다. 그래서 이 글의 콜센터 결과는 ranking이 아니라 정답지 정책과 도메인 민감도를 설명하는 자료로 읽어야 한다.
결론: 벤치마크는 리더보드보다 측정 규칙이다
단일 화자 데이터에서는 Whisper large와 medium이 강한 결과를 보였고, AWS Transcribe는 Whisper base보다 안정적인 결과를 보였다. 하지만 이 결론은 2023년 당시의 공개 제품/공개 모델, 이 레포의 데이터, 당시 CER 산출 방식 안에서만 유효하다. 더 오래 남는 교훈은 특정 모델명이 아니라 측정 방법이다. ASR 품질 평가는 평균 하나로 끝나지 않고, 정답지 정책과 threshold, tail risk를 함께 공개해야 읽는 사람이 결과를 재현하고 해석할 수 있다.