The original question sounded simple: if Korean speech-to-text were attached to a real work process, which model would transcribe it well enough? The more important question appeared only after the testing started: what does "well enough" mean, and under which reference text policy should it be measured?
Original Korean columns: ITDaily ComputerWorld
Context: the metric had to come before the model comparison
Cloud STT products and Whisper models all return transcripts, but they do not fail in the same way. Some outputs only changed spacing. Some wrote spoken numbers as digits. Some broke on proper nouns, loanwords, or domain-specific expressions. Reading the transcripts by eye was not enough. I needed the same audio, the same reference text, and the same error formula across every result.
That is why I built Compute STT Error Rate, the Nlptutti package. The public repository is
computing-Korean-STT-error-rates,
and the benchmark scripts import it as nlptutti. Nlptutti provides get_cer,
get_wer, get_crr, and Korean keyword-pattern utilities. Internally, it uses
Levenshtein edit distance to count substitutions, deletions, and insertions, while fixing whitespace
and punctuation handling in code.
I built it because the denominator mattered. If CER is computed only against the reference length,
transcripts with many insertions can exceed 1 or move outside the range I wanted for repeated comparison.
Nlptutti keeps S+D+I as the error numerator, but uses S+D+I+C as the denominator,
including insertions in the normalized error rate. That small choice made the results easier to compare
across thousands of Korean transcripts.
Process: two test surfaces, not one
The primary benchmark used 3,922 single-speaker utterances. For each shared file_name and
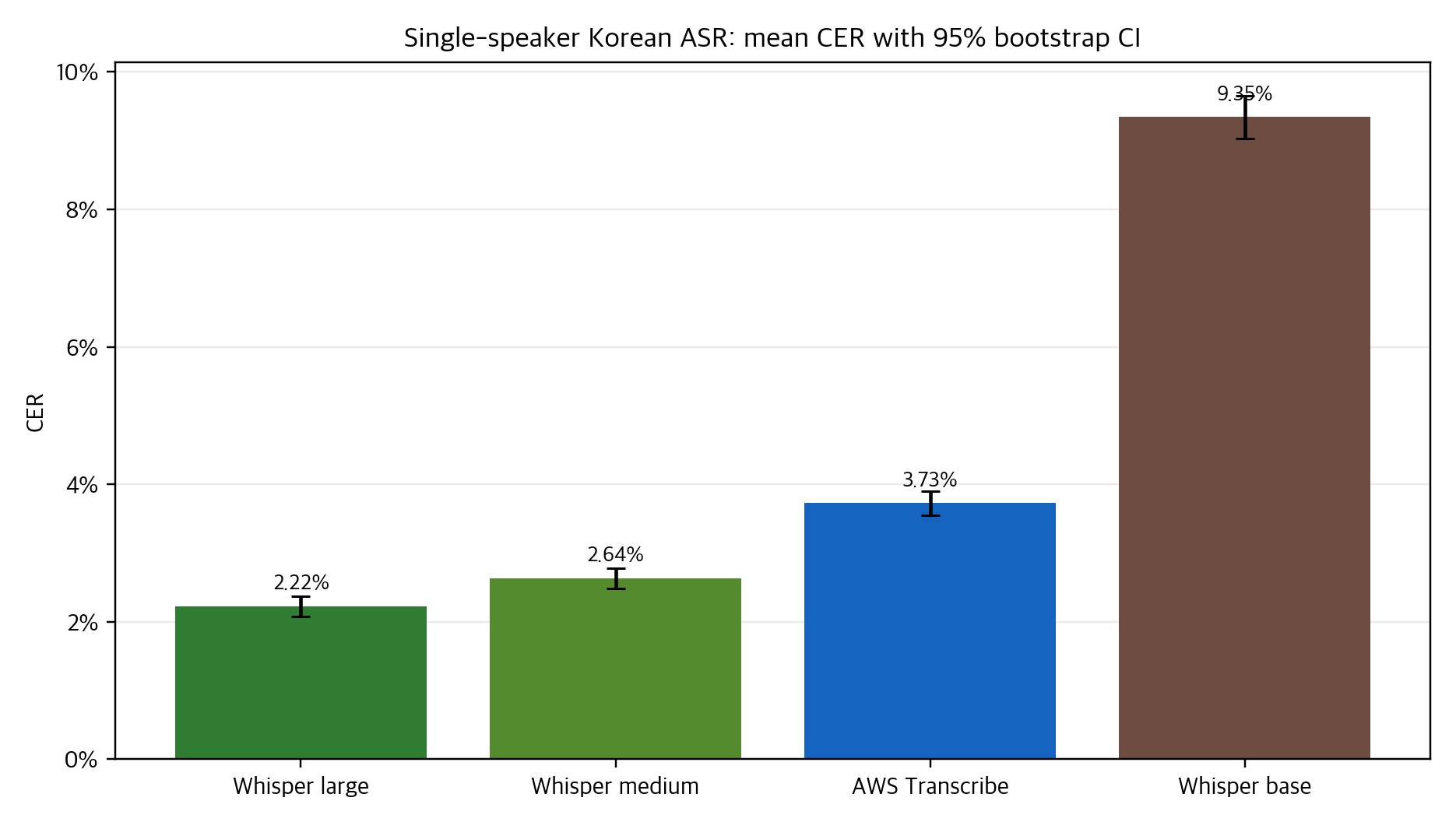
ground_truth, I collected transcripts from AWS Transcribe and Whisper base, medium, and large.
Each row kept the reference sentence, model output, and CER, so the data could be analyzed by mean error,
threshold pass rate, paired delta, and worst-case examples.
The core 3,922 utterances were my own voice data. I recorded them in my home study, the quietest space I had, with a daily target of about 50 sentences. Each sentence was saved as a WAV file through a multi-pattern USB condenser microphone in cardioid pickup mode. The accumulated reading and recording time was close to eight hours. Across roughly three months, I led the experiment design, recording, STT runs, result collection, and metric stabilization.
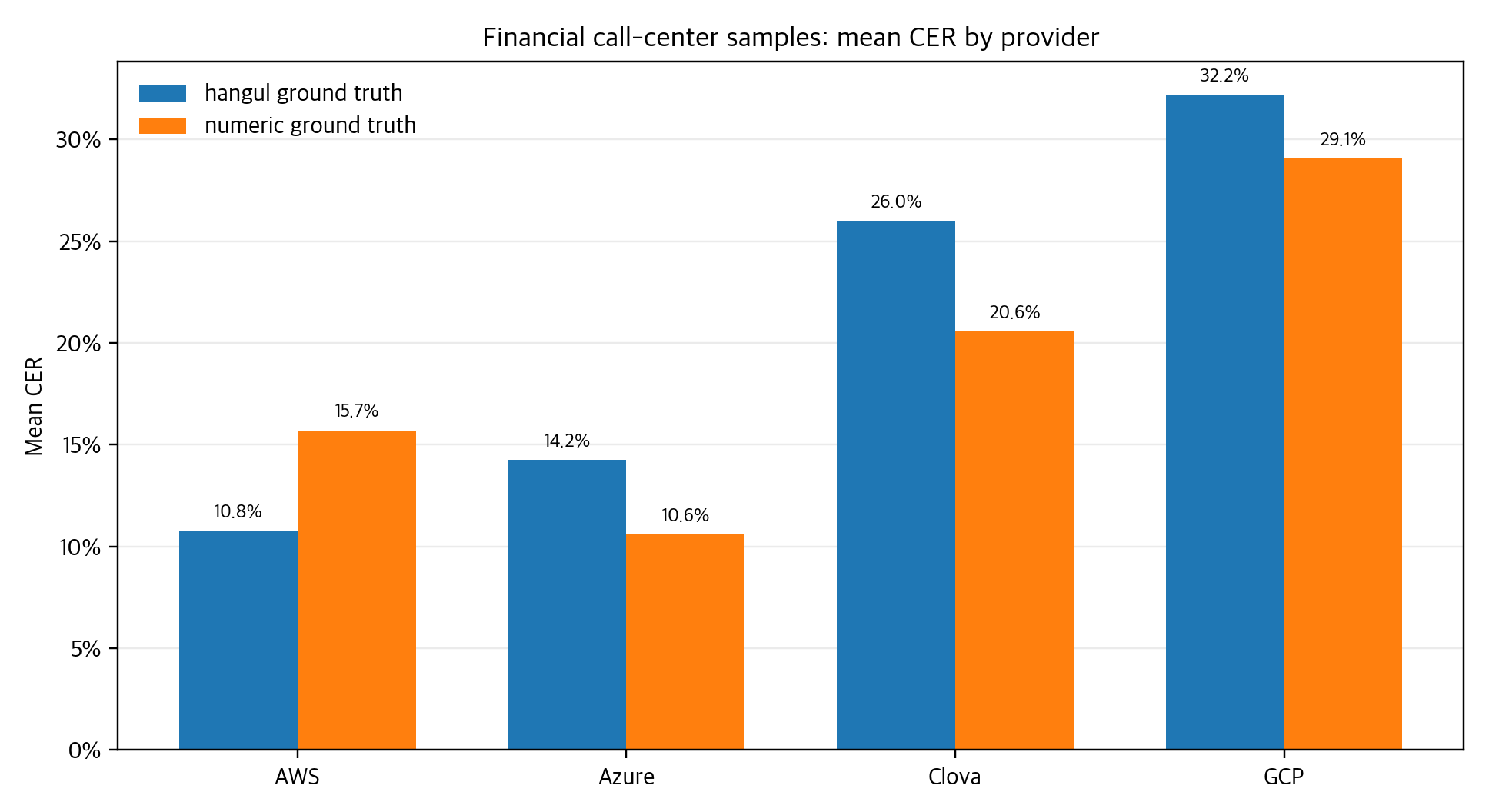
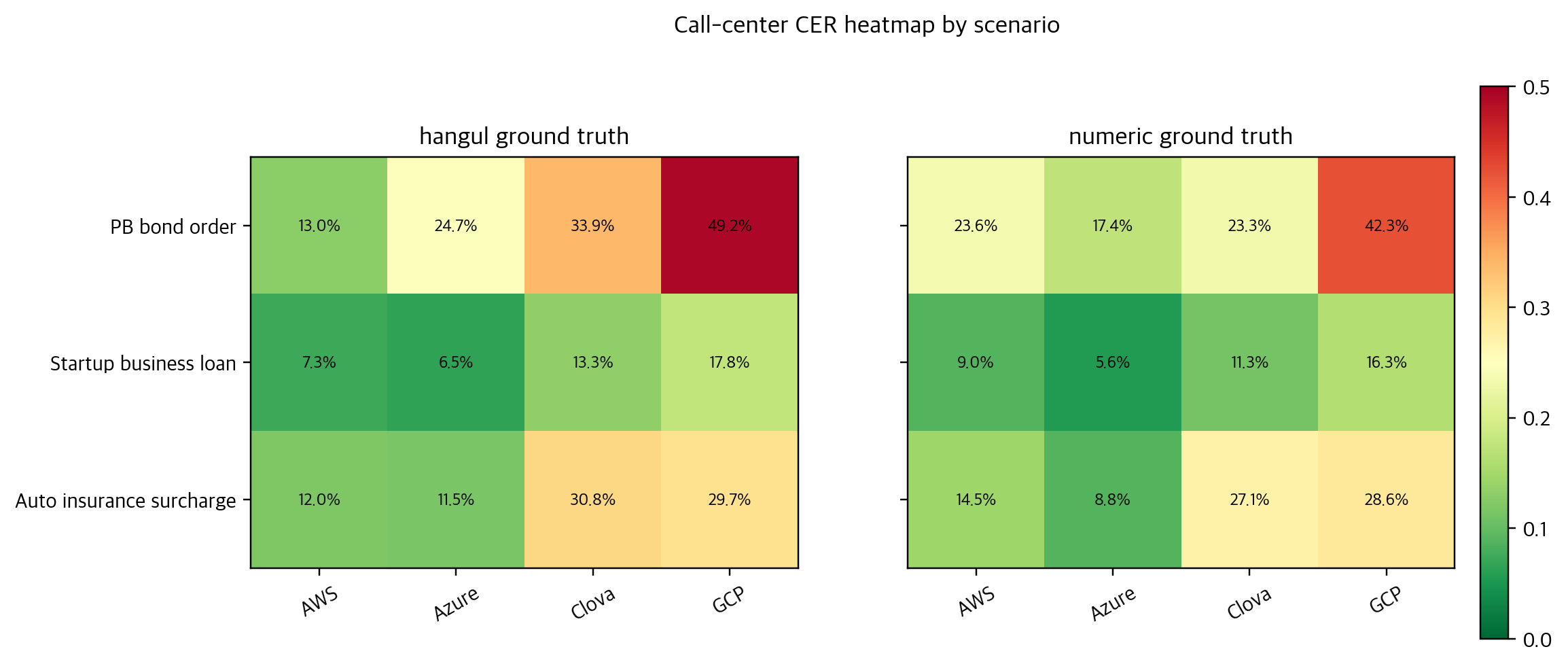
The second surface was a smaller set of three financial call-center personas: PB bond ordering, startup loan guidance, and an auto-insurance premium inquiry. The point was to run a quick practical check on conversations where phone numbers, account numbers, amounts, and dates matter. A few teammates joined a roughly 30-minute meeting and recording session. Because it happened in a meeting room, I used a personally purchased multi-pattern USB condenser microphone in bidirectional pickup mode, trying to capture both sides of a one-to-one conversation evenly. This was not meant to rank providers. It was meant to show how numbers, domain vocabulary, and reference-text policy can move CER in different directions.
Action: average CER was not enough
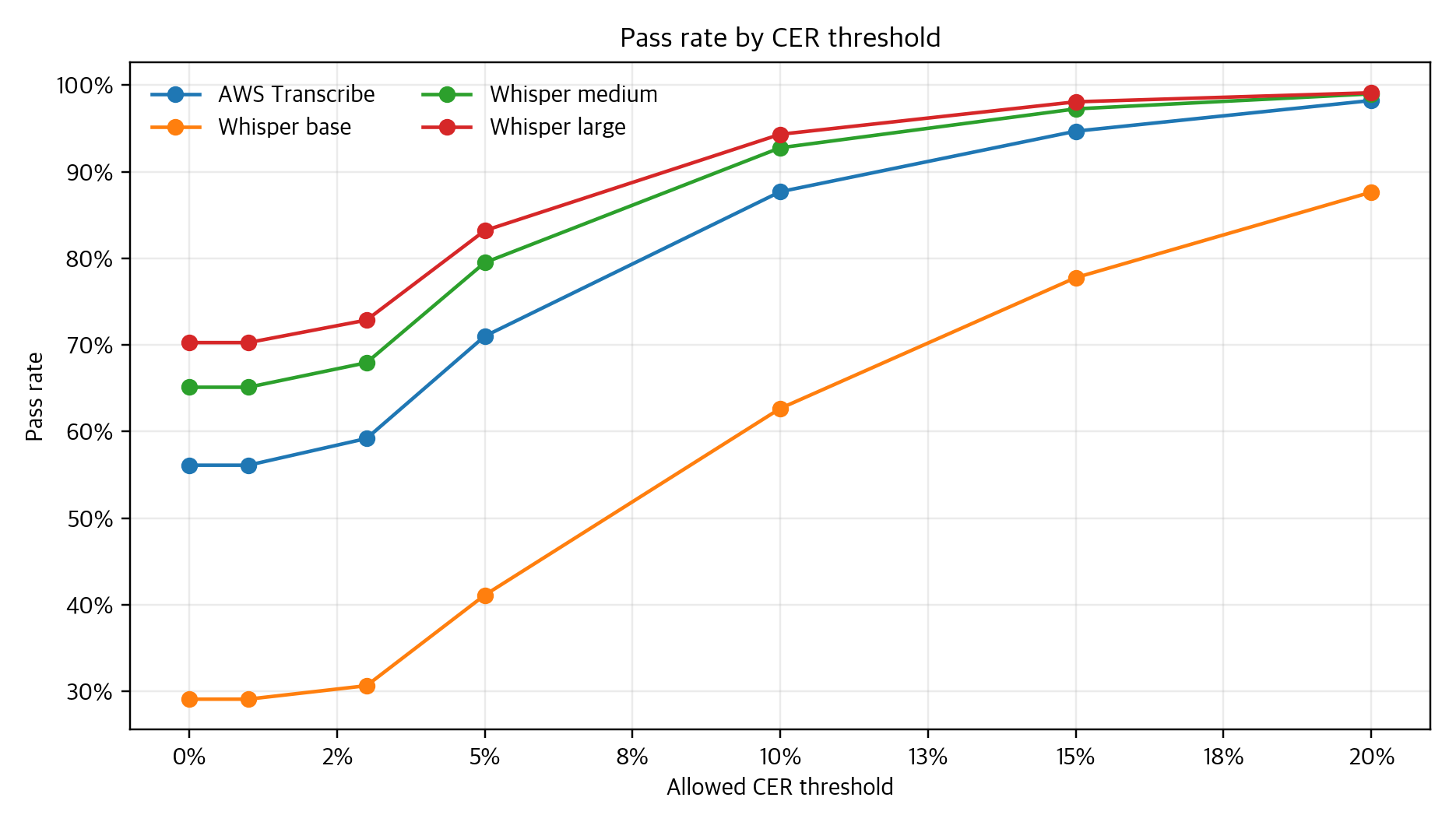
I did not stop at mean CER. A mean gives the general direction, but a workflow cares about different questions: how many sentences can pass automatically, how many remain in a review queue, and where the tail risk lives. So I added perfect recognition rate, 5% pass rate, 10%+ tail risk, paired comparisons, disagreement examples, and call-center heatmaps.
The hardest part was not running one model. It was putting different providers' outputs on the same analytical surface. AWS, Azure, Clova, GCP, and Whisper outputs had different file shapes and transcript structures. In Korean, spacing, punctuation, and numeric notation can change CER materially. In the insurance persona, expressions like account numbers, amounts, and dates repeatedly showed the gap between meaning-level similarity and character-level scoring.
Conclusion: a benchmark is a measurement rule
On the single-speaker data, Whisper large and medium were strong, while AWS Transcribe was more stable than Whisper base. But that conclusion only applies to this repository's 2023 data, public products and models, and the CER policy used at the time. The more durable lesson is the method: ASR quality should be published with reference-text policy, thresholds, and tail risk, not only an average number.