专题文章 · 隐藏的计费面
不可见的推理 token:那笔不出现在答案里的账单
迁移到推理模型之后——或者有人先把推理强度调高之后——回答有时看上去依旧很短、很平常。可见的文本里,丝毫没有"花得更多"的迹象。可财务和遥测对同一个工作负载,看到的却是一张更大的账单。一个很自然的问题就此写出来:既然回答没有变长,成本到底跑哪儿去了?
我们为什么要检验这个
有一个习惯几乎是普遍的:当团队琢磨一个请求的成本时,伸手去抓的是看得见的 东西——回答的长度。短回复感觉便宜,长回复感觉贵。在推理之前的大部分年代里, 这个直觉准得足够好用。
由此就有了一件干净、值得验证的事:也许可见的回答长度真的解释了支出,那张 更大的账单藏在某个没人注意到的、稍微长了一点的回复里;又或者,推理模型打破了 这个直觉,成本转移到了用户永远读不到的隐藏推理 token 上。到底是哪一边在承担 这次变化,图表能给出答案。
于是我们做了拆解。把每个计费请求拆成输入、缓存输入、可见输出、隐藏推理四块, 再把这个拆解放在同一组短事实回答任务里,挨着成本、质量、延迟一起读。结果把 问题敲定了:可见输出在各档推理强度上只动了约 12.7 到 17.9 个 token,而隐藏 推理却动了约 3.7 到 311.5 个 token。成本和延迟随那条隐藏通道一起上涨,而配对的 质量图并没有相称地跟着抬升。下面的单页概览把这条信息一锤定音,随后各节再补上 测得的细节。

问题
如果回答文本依旧很短,多出来的成本到底从哪儿来?
证据
把 benchmark-01 的 token 构成、成本、延迟三张图,当作一条证据链来读。
发现
可见的回答长度几乎没变,隐藏的推理 token 却随着各档推理强度一路上升。
结论
哪怕回答依旧很短,也要用遥测追踪推理 token;把隐藏 token 预算当成回复不会展示的那部分账单来对待。

回答很短,内部的活儿可不短
在 benchmark-01 里,真正有用的意外,并不是 extra-high effort 的成本更高——那本就在预料之中。真正值得注意的是:这笔涨幅里,落到最终回答上的部分有多小。在 minimal effort 下,可见输出平均 12.7 个 token,推理 token 平均 3.7 个;在 extra-high effort 下,可见输出平均 17.9 个 token,推理 token 平均 311.5 个。
也就是说,读者看到的文本,并不是"用了多少计算量"的可靠代理指标。一个短回答可能盖住一笔很大的推理预算;而一个看上去挺像样的回答,只要配对的质量图没动,在经济上仍可能是一笔划不来的买卖。
这张图该怎么读
柱子代表各档推理强度的聚合值,而不是单个请求的直方图。X 轴是推理强度设置,Y 轴是每个请求的平均推理 token。每根柱子下方的小标签,是同一配置的平均可见输出 token 数。
这张图最好从下往上读。先问:可见输出有没有变化到足以解释账单?再去和隐藏推理那根柱子对照。在这类任务里,解释因素不是回答的长度,而是内部的活儿。
源图各自补充了什么
token 构成解释了机制,但单凭它还不够。成本图显示账单在一路膨胀;质量图追问这笔账单有没有换来更好的回答;延迟图显示用户实际感受到的等待。三者凑齐,隐藏的那一面才读得出来——在这组短事实回答任务里,内部 token 增加了、支出增加了、延迟拉长了,却没有相称的质量上行。
这意味着什么
教训不是"推理 token 不好"。它们正是推理模型的本质所在。教训在于:推理 token 需要有活儿可干。如果任务只要求短事实回答,内部推理就可能成为一笔悄无声息的预算泄漏;如果任务需要多步求解,同样这些 token 就可能正是挣来质量提升的那一部分。
这也正是综述文章为什么总把成本、质量、延迟、token 构成并排着摆:账单并不是全都明明白白地写在回答里。
证据表
docs/blog/data/chart-data/token-composition/benchmark-01/tokens.json,
请在证据仪表盘
(分发的图表数据)里阅读。
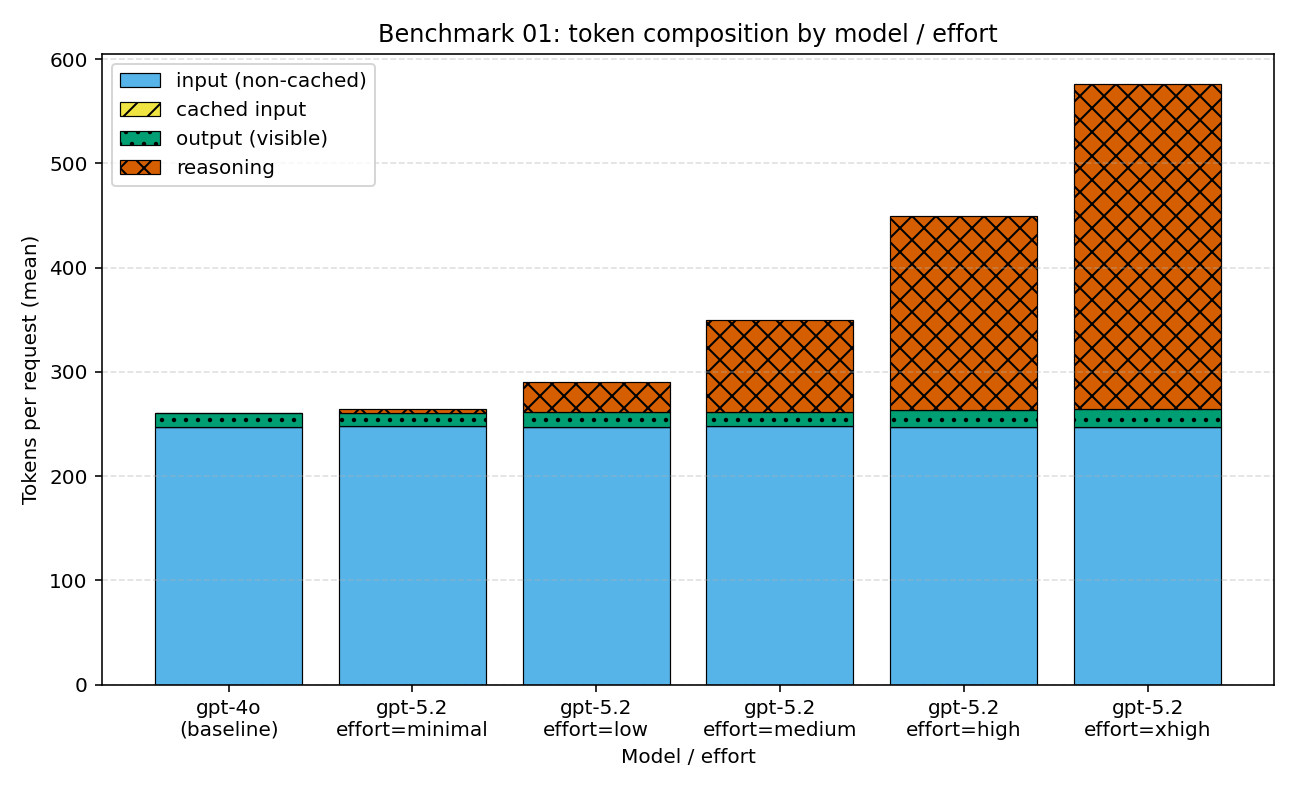
| 证据行 | 指标 A | 指标 B | 它补充了什么 |
|---|---|---|---|
| Minimal effort | 可见输出 token 12.7 | 推理 token 3.7 | 短回答,极小的隐藏预算。 |
| Extra-high effort | 可见输出 token 17.9 | 推理 token 311.5 | 文本依旧很短,内部预算却大得多。 |
| 配对的质量 | minimal 下 1.88 | extra-high 下 1.78 | 在这类任务里,隐藏的活儿并没有带来质量上行。 |
| 延迟 | minimal 下 1.1s | extra-high 下 3.1s | 隐藏的活儿把等待时间也拉长了。 |
来源与证据边界
上面所有数字都能追溯到本仓库的公开产物,所有成本主张都按带日期的定价快照 算出。"把推理 token 预算用遥测显式呈现出来"这一记账习惯,是本文自己的运维 推断。下面两个 Tier 标明了:有文档记载的输入到哪里为止,推断又从哪里开始。
- [1] Tier 1 — 方法论契约:本仓库,
docs/05-methodology.md(v1.0)。每个组合 N = 20 个人工编写样本、R = 3 次重复、仅取公开聚合结果。图表解读正文都立足于这组冻结前提;误差棒是标准差而非置信区间,在 N = 20 下不主张 p 值。 - [2] Tier 1 — PAYG 定价快照:每个请求的成本按本仓库的
pricing/azure-openai-payg-2026-05.yaml算出。来源:Azure OpenAI 定价页(2026-05-19 访问)· 存档。标价一动,隐藏 token 的账单也随之变化。 - [3] Tier 2 — benchmark-01 这组任务的测量:本仓库,
benchmarks/01-short-factual/analysis.json。它是推理 token 从 3.655172 到 311.474576 的变化、可见输出从 12.672414 到 17.881356 的移动、评审分从 1.87931 到 1.779661、延迟从 1112.798745 ms 到 3088.001225 ms 拉长的来源。 - [4] Tier 2 — 渲染后的图表数据:本仓库,
docs/blog/data/chart-data/token-composition/benchmark-01/tokens.json是 token 拆解的来源。与docs/blog/data/chart-data/cost-curves-effort/benchmark-01/cost-per-request.json、quality.json、latency.json一起读,就能佐证:隐藏 token 在没有质量上行的情况下,把账单和等待一并撑大了。 - [5] 证据仪表盘:渲染后的 benchmark-01 token 构成图,是审计同一批产物的可核查形态。
这组测量证明了什么、又没证明什么:它表明,在这类短事实回答任务里,可见输出 几乎没动,内部推理却随推理强度档位一路上升。它并不证明同样的隐藏 token 形态会 出现在多步、工具代理或综合类工作里。每个专题各有自己的测量。
这些证据允许我们说什么
推理 token 预算,哪怕在回答里看不见,也应该在遥测里看得见。这就是本专题为整个系列补上的、最基本的一条记账习惯。
实用准则
- 不要只记总 token,要把推理 token 按请求记录在可见输出旁边。
- 给隐藏 token 预算设置告警,因为短回答也可能背着很大的内部成本。
- 只有当这种工作负载形态下配对的质量图真的动了,才往更高的 effort 提。
实用准则:哪怕可见的回答依旧很短,也要用遥测测量推理 token。隐藏的 token 预算,正是回复不会展示的那部分账单。
下一篇: 多步任务:当推理终于值得一试 — 多花的推理什么时候带来的是质量提升,而不只是一张更大的账单?