विषय-लेख · benchmark-03 टूल-एजेंट
टूल-एजेंट: गुणवत्ता सीलिंग पर पहुँचने के बाद असली फ़र्क़ latency का होता है
जब कोई टीम टूल इस्तेमाल करने वाला एजेंट बनाती है और वह ग़लतियाँ करने लगता है, तो पहली सहज प्रतिक्रिया अक्सर यही होती है: इसे थोड़ा और सोचने दो। यह प्रतिक्रिया तर्कसंगत है — टूल-आधारित काम में योजना, टूल-चुनाव, बीच की स्थिति और जवाब का संयोजन शामिल होता है, इसलिए ज़्यादा reasoning असरदार लगती है। लेकिन एक दूसरी संभावना भी है: अगर टूल-रास्ता काफ़ी अच्छा हो और रूब्रिक पहले से शीर्ष के पास हो, तो अतिरिक्त reasoning स्कोर को वहीं रोके रखकर सिर्फ़ latency और लागत बढ़ा सकती है। benchmark-03 जाँचता है कि टूल-एजेंट के इस हिस्से में कौन-सी व्याख्या सही है।
हमने यह क्यों जाँचा
हालात जाने-पहचाने हैं। टीम टूल इस्तेमाल करने वाला एजेंट जारी करती है, कुछ केसों में उसे चूकते देखती है, और सबसे पहले reasoning effort बढ़ाने का मन करता है। तर्क ठीक है। एजेंट का काम सिर्फ़ याद से जवाब देना नहीं है — उसे योजना बनानी होती है, सही टूल चुनना होता है, बीच की स्थिति सँभालनी होती है, और फिर जवाब जोड़ना होता है। इतनी संरचना वाले काम में "और सोचने दो" पहला स्वाभाविक क़दम लगता है।
लेकिन यहाँ दो अलग व्याख्याएँ जाँचनी पड़ती हैं। हो सकता है अतिरिक्त reasoning सचमुच टूल-योजना सुधारे और जवाब बेहतर करे। या फिर टूल-रास्ता और रूब्रिक मिलकर एक सीलिंग बना दें — एजेंट जैसे ही जवाब तक काफ़ी अच्छा रास्ता पा ले, ज़्यादा reasoning स्कोर को शीर्ष के पास रोके रखे और सिर्फ़ latency व लागत बढ़ाए। benchmark-03 जाँचता है कि अमूर्त बहस नहीं, बल्कि मापे गए हिस्से पर कौन-सी व्याख्या सही बैठती है।
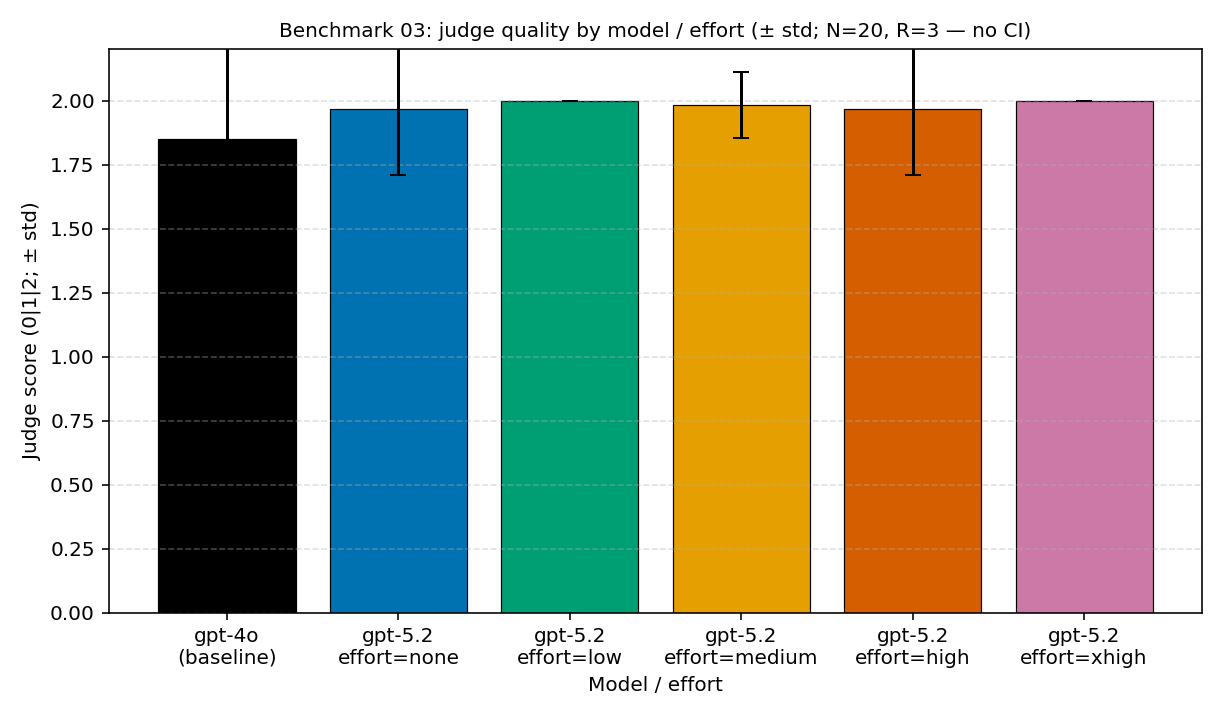
इसलिए हमने इसे मापा। benchmark-03 टूल-एजेंट के इस हिस्से को स्थिर रखता है, उसी मॉडल और effort के स्तरों पर चलता है — GPT-4o baseline, फिर GPT-5.2 का none, low, medium, high, extra-high — और हर configuration में latency, लागत और टोकन-आकार के साथ औसत judge स्कोर पढ़ता है। नतीजा साफ़ है। GPT-5.2 ने GPT-4o baseline के ऊपर गुणवत्ता बढ़ाई, लेकिन GPT-5.2 के भीतर अलग-अलग configurations की गुणवत्ता एक सीलिंग (क़रीब 1.97–2.00) के पास सिमट गई, जबकि लागत, latency और reasoning tokens बढ़ते रहे। नीचे का एक-पृष्ठ सार यही बात एक फ़्रेम में कहता है, और आगे के खंड उसका मापा हुआ विवरण देते हैं।

प्रश्न
टूल-एजेंट की गुणवत्ता पहले से शीर्ष के पास हो, तो अतिरिक्त effort से फिर क्या बदलता है?
सबूत
benchmark-03 के गुणवत्ता, लागत, latency और टोकन-संरचना चार्ट।
नतीजा
GPT-5.2 की गुणवत्ता पूरे effort स्तरों में 1.97–2.00 की सीलिंग पर रही, जबकि लागत प्रति-request $0.002762 से $0.003499 और latency 2.9s से 3.8s तक चढ़ी।
निर्णय
टूल-एजेंट काम को गुणवत्ता-सीलिंग छूने वाले सबसे नीचे effort पर भेजें, और उससे ऊँचे effort को डिफ़ॉल्ट नहीं, बल्कि अलग से जायज़ ठहराने योग्य लागत व latency मानें।

सीलिंग-प्रभाव ही मुख्य बात है
benchmark-03 ने सीधी एकदिश-वृद्धि की कहानी नहीं दी। GPT-4o का judge स्कोर औसतन 1.85 था। GPT-5.2 ने none पर औसत 1.97, low पर 2.0, medium पर औसत 1.98, high पर औसत 1.97 और extra-high पर 2.0 छुआ। यह baseline से गुणवत्ता-सुधार है, पर साथ ही एक सीलिंग भी।
जैसे ही कई combinations शीर्ष के पास सिमट जाती हैं, effort बढ़ाना अपने-आप अर्थपूर्ण नहीं रह जाता। अगला सबूत latency, टोकन-आकार और समुच्चय-स्कोर के भीतर छिपे विफलता-तरीक़ों से आता है।
चार्ट कैसे पढ़ें
यह चार्ट बार-ऊँचाई के लिए latency इस्तेमाल करता है, क्योंकि गुणवत्ता पहले से शीर्ष के पास सिमट चुकी है। X-अक्ष मॉडल/effort combination है, Y-अक्ष औसत latency (मिलीसेकंड)। हर बार के नीचे का लेबल साथ वाला औसत judge स्कोर दिखाता है।
यह चार्ट जानबूझकर हिस्टोग्राम नहीं है। यह सारांशित configurations की आपसी तुलना है। अगर दो configurations की गुणवत्ता पास-पास है, तो छोटा बार यह सवाल उठाता है कि लंबा इंतज़ार करने से क्या कोई साफ़ दिखने वाला फ़ायदा मिल रहा है।
टूल व्याख्या क्यों बदल देते हैं
टूल-एजेंट काम में टूल-चुनाव, बीच की स्थिति और जवाब का संयोजन शामिल हैं। यही उसे छोटे तथ्यात्मक काम से ज़्यादा माँग वाला बनाता है। साथ ही इसका मतलब यह भी है कि समुच्चय गुणवत्ता-स्कोर अलग तरह के व्यवहार छिपा सकता है। कोई configuration इसलिए पास हुई हो कि टूल ने ज़्यादातर काम कर दिया, या सही टूल इस्तेमाल करने के बावजूद ख़राब सारांश की वजह से नीचे गई हो।
चार्ट जाँच की ज़रूरत ख़त्म नहीं करता — यह बताता है कि कहाँ देखना है। इस रन में आकर्षक क्षेत्र इस पर निर्भर करता है कि आपका मानक कहाँ है। अगर सख़्त 2.00 चाहिए, तो वहाँ पहले पहुँचने वाला combination low है। अगर शीर्ष के क़रीब का स्कोर ही रूब्रिक पूरा कर देता है, तो baseline जैसी latency के क़रीब काम पूरा करने वाला combination none है। दोनों हाल में चाल वही है — मानक पूरा करने वाला सबसे नीचे combination ढूँढो, और ऊँचे effort पर जाने से पहले लागत व latency देखो।
याद रखने योग्य बिंदु
टूल-एजेंट बेंचमार्क को दो तरह से देखना पड़ता है। पहले पूछो कि क्या reasoning ने सहीपन सुधारा। फिर, अगर गुणवत्ता शीर्ष के पास जम गई है, तो पूछो कि कौन-सा combination latency और टोकन के दबाव को क़ाबू में रखता है। दूसरा सवाल बाद में याद आने वाली बात नहीं है — यही नतीजे को बेंचमार्क के बाहर इस्तेमाल लायक़ बनाता है।
सबूत की तालिका
docs/blog/data/chart-data/cost-curves-effort/benchmark-03/quality.json
से आते हैं; एविडेंस डैशबोर्ड
(परोसा गया चार्ट-डेटा) में
latency और लागत चार्ट के बग़ल में पढ़ें।
| सबूत-पंक्ति | मीट्रिक A | मीट्रिक B | क्या जुड़ता है |
|---|---|---|---|
| GPT-4o baseline | judge स्कोर 1.85 | औसत latency 3.0s | मज़बूत baseline, पर सीलिंग नहीं। |
| GPT-5.2 none | judge स्कोर 1.97 | औसत latency 2.9s | लगभग वही latency पर गुणवत्ता ऊपर। |
| GPT-5.2 low | judge स्कोर 2.00 | औसत latency 3.1s | थोड़ी latency-वृद्धि पर सीलिंग स्कोर। |
| GPT-5.2 extra-high | judge स्कोर 2.00 | औसत latency 3.8s | वही सीलिंग स्कोर, पर ज़्यादा धीमा। |
स्रोत और सबूत-सीमा
ऊपर का हर मान इस रिपॉज़िटरी की किसी सार्वजनिक कलाकृति तक जाता है, और हर लागत-दावा एक दिनांकित मूल्य-स्नैपशॉट पर आधारित है। गुणवत्ता-सीलिंग छूते ही सबसे नीचे effort पर रुकने की जो सलाह यह लेख देता है, वह इसकी अपनी संचालन-व्याख्या है। नीचे की दो श्रेणियाँ बताती हैं कि प्रलेखित इनपुट कहाँ ख़त्म होता है और अनुमान कहाँ से शुरू होता है।
- [1] Tier 1 — कार्यप्रणाली अनुबंध: यह रिपॉज़िटरी,
docs/05-methodology.md(v1.0)। प्रति combination N = 20 लिखित नमूने, R = 3 दोहराव, केवल सार्वजनिक समुच्चय का यह हिस्सा। चार्ट की व्याख्या इसी स्थिर रुख़ को मानती है; त्रुटि-बार मानक विचलन हैं, और N = 20 पर p-मान का दावा नहीं। - [2] Tier 1 — PAYG मूल्य स्नैपशॉट: प्रति-request लागत इस रिपॉज़िटरी की
pricing/azure-openai-payg-2026-05.yamlपर गणित है — यह Azure OpenAI के आधिकारिक सार्वजनिक मूल्य-पृष्ठ का 2026-05-19 को लिया गया फ़्रोज़न स्नैपशॉट है। सूची-मूल्य हिलने पर लागत-संख्याएँ भी बदलेंगी। - [3] Tier 2 — benchmark-03 हिस्से का मापन: यह रिपॉज़िटरी,
benchmarks/03-tool-using-agent/analysis.json। सीलिंग-प्रभाव वाले गुणवत्ता-बार — 1.85 GPT-4o baseline और 1.97 (none), 2.00 (low), 1.98 (medium), 1.97 (high), 2.00 (extra-high) की पट्टी में रहने वाले GPT-5.2 effort स्तर — और latency के 2.9s से 3.8s तक बढ़ने के साथ प्रति-request $0.002762 (none) से $0.003499 (extra-high) तक लगातार बढ़ती संगत लागत का यही स्रोत है। - [4] Tier 2 — रेंडर किया गया चार्ट-डेटा: यह रिपॉज़िटरी,
docs/blog/data/chart-data/cost-curves-effort/benchmark-03/cost-per-request.json,quality.json,latency.json। इन्हेंdocs/blog/data/chart-data/token-composition/benchmark-03/tokens.jsonके साथ पढ़ने पर यह सबूत मिलता है कि reasoning tokens प्रति-request 0 से 52.15 तक बढ़े, फिर भी गुणवत्ता-बार सीलिंग से नहीं हिले। - [5] एविडेंस डैशबोर्ड: रेंडर हुआ benchmark-03 गुणवत्ता–लागत जोड़ी चार्ट उन्हीं कलाकृतियों का ऑडिट-योग्य रूप है।
यह मापा गया हिस्सा क्या सिद्ध करता है और क्या नहीं: इस टूल-एजेंट हिस्से में reasoning effort बढ़ाने पर गुणवत्ता सीलिंग से टकराई — GPT-5.2 का स्कोर 1.97–2.00 पट्टी से बाहर नहीं गया — जबकि लागत effort के स्तरों के साथ बढ़ती रही। लेकिन यह सिद्ध नहीं करता कि वही सीलिंग छोटे तथ्यात्मक, multi-step या इंटीग्रेशन काम में भी उसी effort स्तर पर दिखेगी। हर विषय का अपना मापन है।
इस सबूत से क्या कहा जा सकता है
टूल-एजेंट काम में काम का वाक्य "effort बढ़ाओ" नहीं है। यह है: "सचमुच ज़रूरी एजेंट-व्यवहार बनाए रखने वाला सबसे नीचे effort ढूँढो।"
व्यावहारिक नियम
- गुणवत्ता-चार्ट को सिर्फ़ गुणवत्ता-बार से नहीं, उसी benchmark-03 combination के लागत-चार्ट और latency-चार्ट के साथ जोड़कर पढ़ें।
- गुणवत्ता-मानक — सख़्त 2.00 हो या स्वीकार्य शीर्ष-पास स्कोर — पूरा करने वाला सबसे नीचे effort combination ढूँढें और उसे डिफ़ॉल्ट बनाएँ।
- उससे ऊँचे effort को दृश्य स्कोर-हलचल से जायज़ ठहराने योग्य लागत व latency मानें।
- भरोसा करने से पहले समुच्चय जाँचें। पास हुआ combination रीज़निंग नहीं, टूल पर टिका हो सकता है।
- वर्कलोड-आकार बदलने पर दोबारा मापें। यह सीलिंग टूल-एजेंट काम तक सीमित है।
व्यावहारिक नियम: इस टूल-एजेंट हिस्से में गुणवत्ता सीलिंग छू ले तो reasoning effort बढ़ाना बंद करें। अतिरिक्त effort से ऊँचा स्कोर नहीं मिला, सिर्फ़ लागत और latency बढ़ी।
आगे: PTU/PAYG क्रॉसओवर: क्षमता का नतीजा नहीं, योजना की रेखा — वर्कलोड साइज़ करने के बाद प्रोविज़न्ड throughput कब PAYG से ऊपर निकलता है?