운영 에세이 · 프롬프트 캐싱과 라우팅 힌트
캐시 키: 라벨이 아니라 라우팅 힌트
어떤 팀이 prompt_cache_key를 붙이면서 여느 라벨과 똑같이
다룹니다. 자연스러운 반사 동작은 호출을 고유하게 식별하는 무엇이든 채워
넣는 것입니다 — request_id, 사용자의 질문 텍스트,
타임스탬프, 또는 서로를 구분할 만큼 촘촘한 테넌트별·사용자별 축 같은 것
말입니다. 하지만 이 필드는 라벨보다 운영적입니다. 프롬프트 프리픽스
해시와 결합되어 일치하는 작업이 어디로 라우팅될지에 영향을 줍니다. 그래서
키를 구체적으로 만들려는 직관은 곧장 이 글이 던지는 운영 질문과
부딪힙니다 — 더 고유한 키는 재사용을 모을까요, 아니면 공유
프리픽스가 애써 얻어 낸 캐시 지역성을 흩뜨릴까요?
prompt_cache_key는 반복 작업을 한 머신으로 라우팅하고,
Microsoft Learn은 버킷마다 분당 약 15개 요청을 넘어서면 캐시 효율이
떨어질 수 있는 지점을 문서화합니다. 이 한 장 요약은 한 가지
메시지만 전합니다 — 문서화된 천장 아래에 머물도록 버킷 크기를
잡으세요 — 그리고 경계를 표시합니다. 천장은 공식 사양이고, 그 옆의
적중률과 지연 형태는 PAYG에서 측정한 정제된 공개 집계로, 서술적으로만
제시합니다.
캐시 키 버킷팅 한 장 요약 SVG 열기.

추측 대신 키 크기를 잡는 이유
고유 키를 넣고 싶어지는 반사적 선택은 구체성이 공짜라고 — 더 촘촘한 키는 요청을
구분하는 데 도움만 줄 뿐이라고 — 전제합니다. 그 전제를 받아들이기
전에 두 가지를 나란히 놓아 볼 만합니다. 첫째는 Microsoft Learn이
문서화하는 내용입니다. 프롬프트 캐싱은 캐시 적격 조건으로 동일한 앞부분
프리픽스를 요구하고, prompt_cache_key는 프리픽스 해시와
결합되어 반복 작업이 어디에 떨어질지를 조종합니다. 같은 문서는 대략적인
지점 하나를 표시합니다 — 하나의 프리픽스+키 조합에 대해 분당 약
15개 요청 — 이를 넘어서면 트래픽이 추가 머신으로 흘러넘치고 캐시
효율이 떨어질 수 있습니다. 둘째는 이 저장소의 원천 실행에서 나온 희소한
정제 공개 집계로, 같은 프리픽스를 더 많은 버킷으로 쪼갤 때 캐시 적중률과
첫 토큰 지연이 실제로 어떻게 움직였는지를 보여 주려고 서술용으로
포함합니다.
잠시 멈춰 볼 부분은 그 짝짓기입니다. 적중률만 보면 그 아래에서 사용자 경험이 바뀌는 동안에도 안심되게 읽힐 수 있습니다. 이 구간에서는 버킷 수가 늘어나는 동안에도 적중률이 높고 거의 평평하게 유지되어, 그 값만 읽으면 쪼개기에 비용이 들지 않은 것처럼 보입니다. 나머지 절반의 이야기는 첫 토큰 지연의 꼬리가 들려줍니다 — 뜨거운 버킷 하나가 매우 큰 p95를 지고 있었는데, 트래픽을 더 많은 버킷으로 분산하자 그 값이 가파르게 떨어졌습니다. 그래서 운영의 질문은 “캐시가 적중했는가?”가 아니라 “각 버킷이, 한 버킷만 너무 뜨거워지지 않으면서 프리픽스가 지역성을 유지하도록 크기가 잡혀 있는가?”입니다. 프리픽스 해시 라우팅과 분당 약 15개 요청이라는 대략적 오버플로 지점은 Microsoft Learn이 문서화하는 내용이고, 버킷 수 계산과 적중률·지연을 함께 보여 주는 공개 자료는 보편적인 캐시 적중 곡선이 아니라 이 저장소가 옹호하는 운영적 추론이자 원천 실행 근거입니다. 아래 차트가 그 짝짓기를 명시적으로 보여 줍니다.
질문
공유 프롬프트 프리픽스는 몇 개의 캐시 키 버킷을 사용해야 할까요?
근거
Microsoft Learn은 라우팅 힌트와 대략적인 오버플로 지점을 정의하고, 이 저장소는 희소한 공개 측정을 더합니다.
결정
워크로드 단위로 버킷을 나누고, 버킷별 비율을 위험 구간 아래로 유지하며, 적중률과 첫 토큰 지연을 함께 모니터링하세요.
공식 동작 · 키가 바꾸는 것
동일한 프리픽스에서 시작하는 캐시
Microsoft Learn에 따르면 프롬프트 캐싱에는 최소 1,024개의 입력 토큰이 필요하며 처음 1,024개 토큰이 동일해야 합니다. 초기 프리픽스는 라우팅을 위해 해시되고, 처음 1,024개 토큰 이후에는 추가 캐시 일치가 128개 토큰 단위로 발생합니다. 처음 1,024개 토큰 안에서 단 한 글자만 달라져도 캐시 적중이 미스로 바뀔 수 있습니다.
프리픽스가 먼저
반복되는 지시문, 스키마, 도구, 예시를 앞쪽에 두세요. 프리픽스가 바뀌면 뒤쪽 재사용은 덜 유용합니다.
키가 그다음
prompt_cache_key는 프리픽스 해시와 결합되어 반복 작업의 라우팅에 영향을 줍니다.
보장은 결코 없음
키는 재사용 확률을 높이지만 적중을 약속하지는 않습니다. 운영 힌트로 다루세요.
크기 산정 · 버킷을 위험 구간 아래로 유지
버킷 수의 트레이드오프: 하나는 너무 뜨겁고, 다수는 너무 차가움
Microsoft Learn은 대략적인 오버플로 지점을 설명합니다. 동일한
프리픽스와 prompt_cache_key 조합이 분당 약 15개
요청을 초과하면 일부 요청이 추가 머신으로 라우팅되어 캐시
효율이 떨어질 수 있습니다. 실무적인 크기 산정 규칙은 공유
프리픽스를 충분히 안정적인 버킷으로 나누어 각 버킷이 여유를
두고 그 위험 구간 아래에 머무르도록 하는 것입니다.
버킷 개수 규칙
common_prefix_rpm = common_prefix_tps × 60
minimum_buckets = ceil(common_prefix_rpm / 15)
recommended_buckets = ceil(common_prefix_rpm / target_rpm_per_bucket)
계산 예시
1.4 TPS에서 공통 프리픽스는 84 RPM을 봅니다. 15-RPM 하한은 6개 버킷을, 10-RPM 목표는 9개를 줍니다.
단일 버킷의 한계
겉으로 보이는 프롬프트가 안정적이어도 단일 핫 버킷은 로컬 캐시 경로를 넘칠 수 있습니다.
고유 키의 한계
호출마다 고유한 키는 재사용이 쌓이는 것을 막습니다. 캐시가 재사용을 쌓을 기회 자체가 없습니다.
관측된 근거 · 희소한 공개 자료
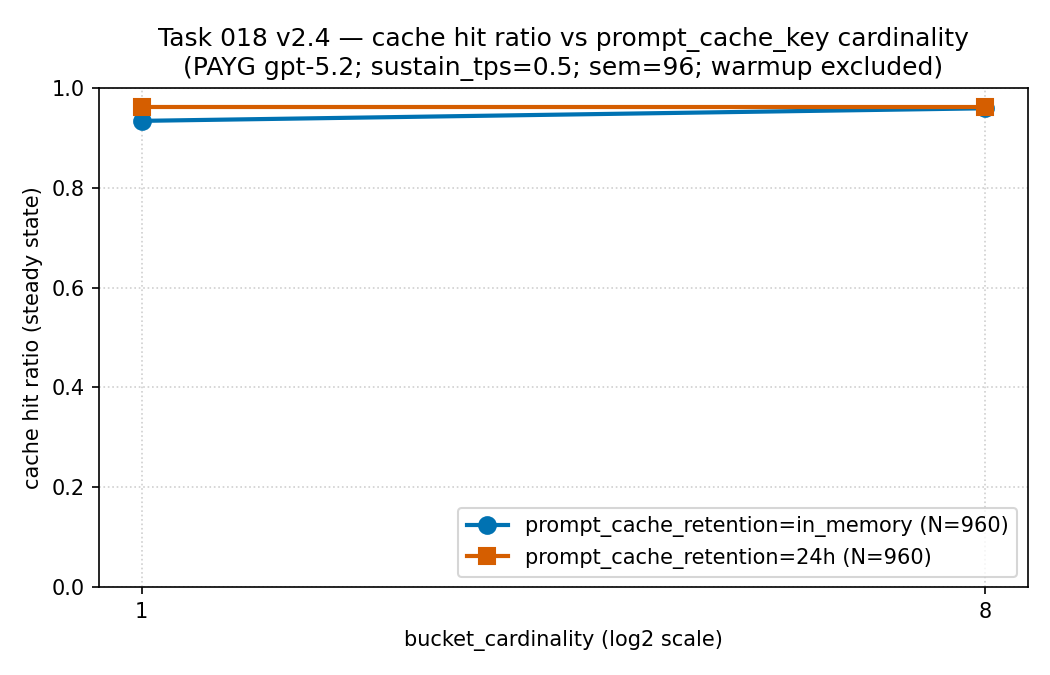
적중률과 지연을 함께 읽기

in_memory와 24h — 이며 각각 N = 960
레코드로, 빈도 히스토그램이 아니라 두 계열 선 차트입니다.
읽는 법: 버킷별 비율이 낮은 이 구간에서는
카디널리티가 올라가도 적중률이 높고 거의 평탄하게(약 0.93~0.96)
유지되었습니다. 즉 프리픽스를 더 많은 버킷으로 나누는 것만으로는
여기서 적중률이 무너지지 않았습니다 — 조각화 비용은 이 패널이 아니라
다음 패널의 지연 꼬리에서 나타났습니다. 근거 경계:
단일 테넌트·리전의 PAYG gpt-5.2에서 측정한 희소하고 정제된 공개
집계(PTU 아님)이며, 보편적인 캐시 적중 곡선이 아니라 서술적
자료입니다. 출처: 값은 이 저장소의
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv
에서 가져옵니다 (원천 CSV).
in_memory 버킷은 매우 큰 p95(약 106,000 ms)를
기록했고, 트래픽이 8개 버킷으로 분산되자 가파르게
떨어졌습니다(약 16,600 ms). 반면 24h 계열은 내내 더
낮게 유지되었습니다 — 즉 이 구간에서는 버킷팅 비용이 지연 꼬리에
실렸고, 그래서 적중률은 단독이 아니라 첫 토큰 지연과 함께 읽어야
합니다. 근거 경계: 동일한 희소·정제 공개 집계로
PAYG gpt-5.2(PTU 아님)이며, 지연 보장이 아니라 서술적 자료입니다.
출처:
results/cache-key-bucketing/ttft_p95_vs_cardinality.csv
(원천 CSV).
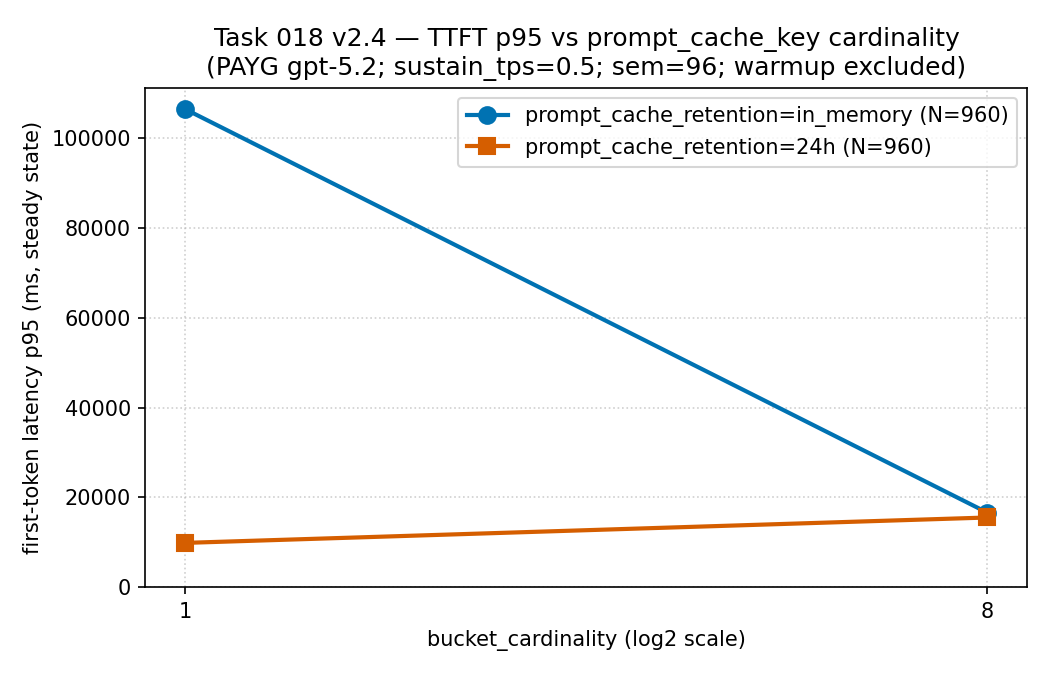
| 보존 | 카디널리티 | 적중률 | TTFT p95 | 버킷별 RPM |
|---|---|---|---|---|
| in-memory | 1 | 0.9334 | 106,389.96 ms | 30.65 |
| in-memory | 8 | 0.9586 | 16,623.66 ms | 4.00 |
| 24h | 1 | 0.9612 | 9,899.74 ms | 30.73 |
| 24h | 8 | 0.9612 | 15,549.08 ms | 4.00 |
이것이 증명하는 것과 증명하지 못하는 것
이 공개 자료는 보편적인 임계 곡선을 증명하지 않습니다. 다만 운영자가 적중률만 봐서는 안 되는 이유를 보여줍니다. 보존 모드, 버킷 비율, 첫 토큰 지연이 모두 사용자 경험을 움직입니다.
키 설계 · 안정적인 워크로드 버킷
버킷 기준: 호출이 아니라 워크로드 단위
좋은 키는 동일한 워크로드에 대해 결정적이어야 합니다. 나쁜 키는 호출마다 달라지는 엔트로피를 담습니다. 타임스탬프, UUID, 무작위 접미사, 또는 고유한 호출 토큰이 키에 들어가면 캐시 키 공간이 폭발하고 프리픽스가 재사용을 쌓을 수 없습니다.
권장 패턴
tenant:flow:locale:schema는 동일한 에이전트, 스키마, 로케일, 작업 형태를 함께 묶습니다.
피해야 할 패턴
고유 id, 타임스탬프, 무작위 UUID, 원시 사용자 질문은 호출마다 버킷 하나를 만듭니다.
모니터링
버킷별 RPM, 캐시된 토큰 비중, 첫 토큰 지연을 추적하세요. 트래픽 형태가 바뀌면 크기를 조정하세요.
출처와 근거 경계
Tier 1 — 서비스 계약(Microsoft Learn). 프롬프트 캐싱
프리픽스 규칙, 프리픽스 해시 라우팅, 128개 토큰 단위 일치 단계, 단 한
글자의 미스, prompt_cache_key 라우팅 힌트, 그리고 분당 약
15개 요청의 오버플로 지점이 여기에 문서화되어 있습니다.
- [1] Prompt caching with Azure OpenAI — 1,024 토큰 최소
요건과 동일 프리픽스 요구, 초기 프리픽스 해시 기반 라우팅, 처음
1,024개 이후 추가로 동일한 128개 토큰마다의 캐시 일치, 단 한 글자의
캐시 미스, 프리픽스 해시와 결합되어 라우팅에 영향을 주는
prompt_cache_key힌트, 그리고 동일 프리픽스·키 요청이 추가 머신으로 넘쳐 캐시 효율이 떨어지는 분당 약 15개 요청 지점을 정의합니다. 출처: Microsoft Learn 문서 (2026-06-04 접근) · 아카이브.
Tier 2 — 운영적 추론(이 저장소). 버킷 개수 계산과 공개 적중률 자료는 Learn 사양이 아니라 이 저장소의 운영적 추론이자 소스 실행 근거입니다.
- [2] 이 저장소,
docs/12-prompt-cache-key-policy.md— 버킷 크기 산정 런북: 문서화된 약 15-RPM 수치에서minimum_buckets = ceil(common_prefix_rpm / 15)를 도출하며,recommended_buckets공식과 기본 버킷당 10-RPM 목표는 Learn 사양이 아니라 이 저장소의 운영적 추론입니다. 출처. - [3] 이 저장소,
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv— 적중률과 첫 토큰 지연 표의 바탕이 된 희소한 공개 집계 자료로, 보편적 곡선이 아니라 소스 실행 근거입니다. 출처.
이 주제가 증명하는 것과 증명하지 못하는 것. 접근일
기준 Microsoft Learn이 명시하는 프롬프트 캐싱 계약 — 1,024 토큰
프리픽스 규칙, 프리픽스 해시 라우팅, prompt_cache_key 힌트,
분당 약 15개 요청의 오버플로 지점 — 과, 공유 프리픽스를 각 버킷이
여유를 두고 그 지점 아래에 머물도록 충분히 안정적인 버킷으로 나누는
이 저장소의 크기 산정 경험칙을 문서화합니다. 버킷 개수 공식과 공개
적중률 자료는 운영적 추론이자 소스 실행 근거이며, 보장된 캐시 적중
곡선이 아닙니다. 모든 모델·리전·트래픽 형태에서 동일하게 성립하는
보편적 임계값은 증명하지 못합니다.
실무 규칙
실무 규칙: 캐시 가능한 프리픽스를 안정적으로 유지하고, 각
prefix + prompt_cache_key가 문서화된 분당 약 15개 요청의
오버플로 지점 아래에 여유를 두고 머물도록 워크로드 단위로 버킷을
나누며, 캐시 적중률은 어느 한쪽만 믿지 말고 첫 토큰 지연과 함께
읽습니다.
다음 글은 키를 어떻게 버킷팅할지에서, 캐시가 얼마나 오래 살아남아야 하는지로 넘어갑니다.