Operations essay · prompt caching and routing hints
Cache keys are routing hints, not labels
A team wires up prompt_cache_key and treats it like any
other label: the natural reflex is to fill it with whatever uniquely tags
the call — a request_id, the user's question text, a
timestamp, or a per-tenant or per-user axis fine enough to keep them
apart. The field is more operational than a label, though: it is combined
with the prompt prefix hash to influence where matching work is routed. So
the instinct to make the key specific runs straight into the operating
question this essay asks — does a more unique key gather reuse, or
does it fragment the cache locality the shared prefix was built to earn?
prompt_cache_key routes repeated work to a machine, and
Microsoft Learn documents an approximate 15-requests-per-minute point
per bucket above which cache effectiveness can drop. The one-pager
carries that single message — size buckets to stay under the documented
ceiling — and marks the boundary: the ceiling is official spec, while
the hit-ratio and latency shape beside it is a sanitized public
aggregate measured on pay-as-you-go, shown descriptively.
Open the cache-key bucketing one-pager SVG.

Why size the key instead of guessing
The unique-key reflex assumes specificity is free — that a finer
key can only help tell requests apart. Before accepting that, two things
are worth putting side by side. The first is what Microsoft Learn
documents: prompt caching requires an identical early prefix for cache
eligibility, and prompt_cache_key is combined with the prefix
hash to steer where repeated work lands; the same documentation marks an
approximate point — about 15 requests per minute for one
prefix-plus-key combination — above which traffic can spill to
extra machines and cache effectiveness can drop. The second is a sparse
sanitized public aggregate from this repository's source runs, included
descriptively to show how cache hit ratio and first-token latency
actually moved as the same prefix was split into more buckets.
The pairing is the part worth pausing on. Hit ratio alone can read as reassuring while the experience underneath shifts: in this slice the hit ratio stayed high and roughly flat as bucket cardinality rose, so reading it by itself would suggest the splitting cost nothing. The first-token latency tail tells the other half of the story — a single hot bucket carried a very large p95 that fell sharply once traffic was spread across more buckets. That is why the operating question is not “did the cache hit?” but “is each bucket sized so the prefix keeps its locality without one bucket running too hot?” The prefix-hash routing and the approximate 15-requests-per-minute overflow point are what Microsoft Learn documents; the bucket-count math and the public hit-ratio-beside-latency slice are operational inference and source-run evidence this repository defends, not a universal cache-hit curve. The charts below make that pairing explicit.
Question
How many cache-key buckets should a shared prompt prefix use?
Evidence
Microsoft Learn defines the routing hint and approximate overflow point; this repo adds sparse public measurement.
Decision
Bucket by workload, keep per-bucket rate below the risk zone, and monitor hit rate plus first-token latency.
Official behavior · what the key changes
The cache starts with an identical prefix
Microsoft Learn says prompt caching needs at least 1,024 input tokens and the first 1,024 tokens must be identical. The initial prefix is hashed for routing, and after the first 1,024 tokens, additional cache matches happen in 128-token steps. A single character difference inside the first 1,024 tokens can turn the cache hit into a miss.
Prefix first
Put repeated instructions, schemas, tools, and examples early. Late reuse is less useful if the prefix changes.
Key second
prompt_cache_key is combined with the prefix hash to influence routing for repeated work.
Guarantee never
The key improves the odds of reuse; it does not promise a hit. Treat it as an operating hint.
Sizing · keep buckets below the risk zone
One bucket can be too hot; too many buckets can be too cold
Microsoft Learn describes an approximate overflow point: when the same
prefix plus prompt_cache_key combination exceeds about 15
requests per minute, some requests can route to extra machines and cache
effectiveness can drop. The practical sizing rule is to split a shared
prefix into enough stable buckets that each bucket stays below that risk
zone with headroom.
Bucket-count rule
common_prefix_rpm = common_prefix_tps × 60
minimum_buckets = ceil(common_prefix_rpm / 15)
recommended_buckets = ceil(common_prefix_rpm / target_rpm_per_bucket)
Worked example
At 1.4 TPS, the common prefix sees 84 RPM. The 15-RPM floor gives 6 buckets; a 10-RPM target gives 9.
Why not one?
A single hot bucket can overflow the local cache path even when the visible prompt looks stable.
Why not unique?
A unique key per call prevents reuse from accumulating. The cache never gets a crowd.
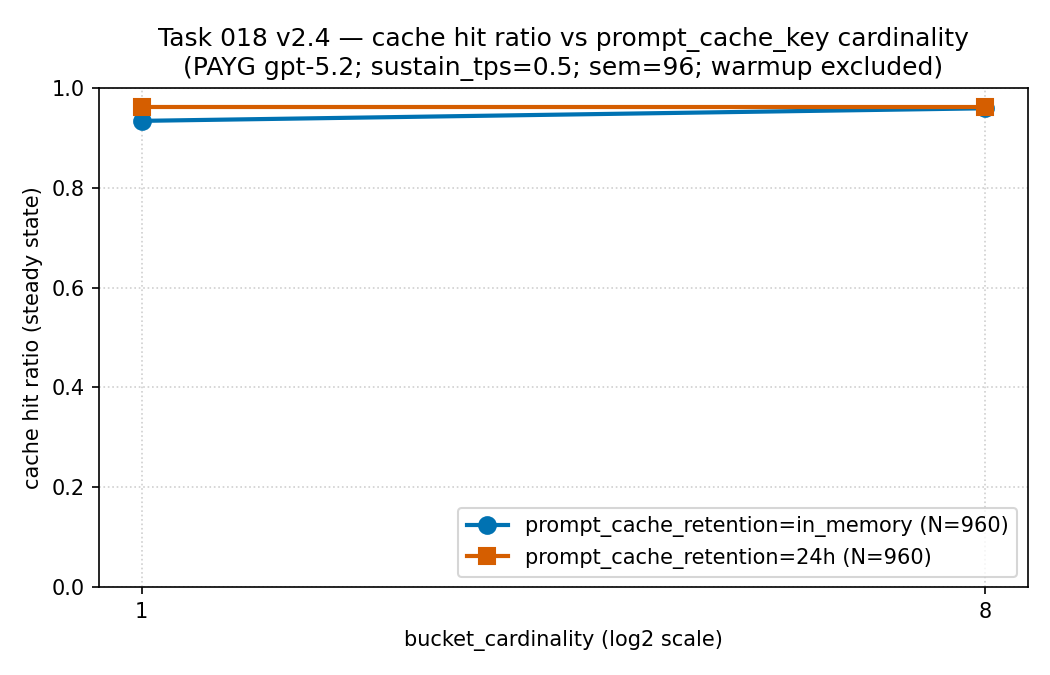
Observed evidence · sparse public slice
Measure hit rate and latency together

in_memory and 24h, each
N = 960 records; this is a two-series line chart, not a
frequency histogram. How to read it: in this low
per-bucket-rate slice the hit ratio stayed high and roughly flat
(about 0.93–0.96) as cardinality rose, so splitting the prefix
into more buckets did not, by itself, collapse the hit ratio here
— the cost of fragmentation appeared in the latency tail in the
next panel, not in this one. Evidence boundary: a
sparse sanitized public aggregate measured on pay-as-you-go gpt-5.2 on
one tenant and region (not PTU); it is descriptive, not a universal
cache-hit curve. Source: values come from this
repository's
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv
(source CSV).
in_memory bucket at cardinality 1 carried a very large
p95 (about 106,000 ms) and fell sharply once traffic was spread
across 8 buckets (about 16,600 ms), while the 24h
series stayed lower throughout — so on this slice the bucketing
cost landed on the latency tail, which is why hit ratio must be read
beside first-token latency rather than alone.
Evidence boundary: the same sparse sanitized public
aggregate on pay-as-you-go gpt-5.2 (not PTU); descriptive, not a
latency guarantee. Source:
results/cache-key-bucketing/ttft_p95_vs_cardinality.csv
(source CSV).
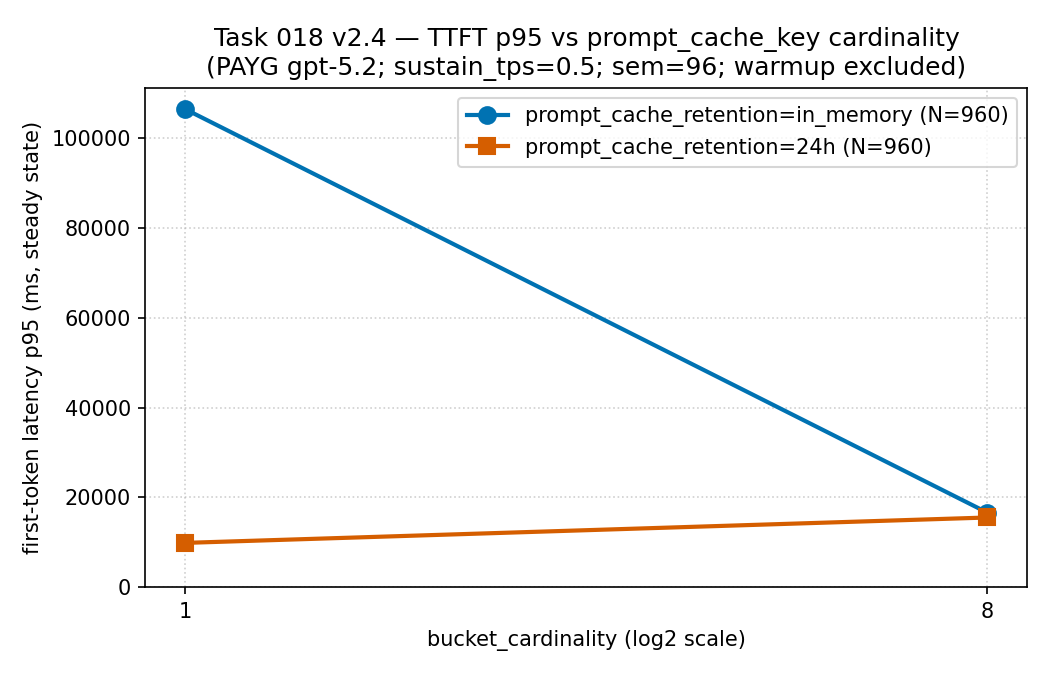
| Retention | Cardinality | Hit ratio | TTFT p95 | Per-bucket RPM |
|---|---|---|---|---|
| in-memory | 1 | 0.9334 | 106,389.96 ms | 30.65 |
| in-memory | 8 | 0.9586 | 16,623.66 ms | 4.00 |
| 24h | 1 | 0.9612 | 9,899.74 ms | 30.73 |
| 24h | 8 | 0.9612 | 15,549.08 ms | 4.00 |
What this does and does not prove
The public slice does not prove a universal threshold curve. It does show why operators should not look at hit ratio alone: retention mode, bucket rate, and first-token latency all move the user experience.
Key design · stable workload buckets
Bucket by workload, not by call
A good key should be deterministic for the same workload. A bad key contains per-call entropy. If a timestamp, UUID, random suffix, or unique call token enters the key, the cache-key space explodes and the prefix cannot build reuse.
Good
tenant:flow:locale:schema keeps the same agent, schema, locale, and task shape together.
Bad
Unique ids, timestamps, random UUIDs, and raw user questions create one bucket per call.
Monitor
Track per-bucket RPM, cached-token share, and first-token latency. Resize when traffic shape changes.
Sources and evidence boundary
Tier 1 — service contract (Microsoft Learn). The
prompt-caching prefix rule, prefix-hash routing, the per-128-token match
step, the single-character miss, the prompt_cache_key
routing hint, and the approximate 15-requests-per-minute overflow point
are documented here.
- [1] Prompt caching with Azure OpenAI — documents the
1,024-token minimum and identical-prefix requirement, routing by a hash
of the initial prefix, a cache match for every 128 additional identical
tokens after the first 1,024, the single-character cache miss, the
prompt_cache_keyhint combined with the prefix hash to influence routing, and the approximate 15-requests-per-minute point above which requests for the same prefix and key overflow to extra machines and cache effectiveness drops. accessed 2026-06-04: https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/prompt-caching; https://web.archive.org/web/20260604174202/https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/prompt-caching.
Tier 2 — operational inference (this repository). The bucket-count math and the public hit-ratio slice are repository operational inference and source-run evidence, not Learn specifications.
- [2] this repository,
docs/12-prompt-cache-key-policy.md— the bucket-sizing runbook: the repository derivesminimum_buckets = ceil(common_prefix_rpm / 15)from the documented approximate 15-RPM figure, while therecommended_bucketsformula and its default 10-RPM-per-bucket target are repository operational inference, not a Learn specification. source. - [3] this repository,
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv— the sparse public aggregate slice behind the hit-ratio and first-token-latency table; source-run evidence, not a universal curve. source.
What this topic does and does not prove. It documents
the prompt-caching contract as Microsoft Learn states it on the access
date — the 1,024-token prefix rule, routing by the prefix hash, the
prompt_cache_key hint, and the approximate
15-requests-per-minute overflow point — plus a repository sizing rule of
thumb: split a shared prefix into enough stable buckets that each stays
below that overflow point with headroom. The bucket-count formula and the
public hit-ratio slice are operational inference and source-run evidence,
not a guaranteed cache-hit curve. It does not prove a universal threshold
that holds identically across every model, region, or traffic shape.
The practical rule
The practical rule: keep the cacheable prefix stable, bucket by
workload so each prefix + prompt_cache_key stays below the
documented approximate 15-requests-per-minute overflow point with
headroom, and read cache-hit ratio beside first-token latency rather than
trusting either alone.
The next essay turns from how to bucket the key to how long the cache should survive.
When cache reuse must survive a short idle window, what must the request say explicitly?