Operations essay · prompt cache retention
Retention is a request policy, not an assumption
Prompt caching can feel automatic, because supported models cache
eligible prefixes by default. So the reflex is to lean on it: a workload
reuses a shared prefix after an idle gap, across a shift boundary, after
a batch pause, or on a later customer turn, and the request body simply
omits prompt_cache_retention and trusts the window to still
be there. But “cached by default” is not the same as
“retained as long as the operation assumes.” If the request
omits retention, the operation may be counting on a cache window it never
asked for — so the operating question is not “is caching
on?” but “did the request actually ask for the reuse window
this workload depends on?”
in_memory default that can clear within minutes and an
explicit 24h window. The one-pager carries that single
message — make retention explicit when later reuse matters — and marks
the boundary: the retention modes are official spec, while the
first-token-latency shape beside them is a sanitized public aggregate
measured on pay-as-you-go, shown descriptively.
Open the cache-retention one-pager SVG.

Why set the window instead of assuming it
The default-is-fine reflex assumes the cache window will outlast the
gap the workload leaves between reuses. Before accepting that, two
things are worth putting side by side. The first is what Microsoft
Learn documents: there are two retention policies,
in_memory and 24h; in-memory entries are
typically cleared within 5 to 10 minutes of inactivity and always
removed within one hour of last use, while extended retention can keep
cached prefixes routable for up to 24 hours; for gpt-5.4
and older models an omitted value means in_memory, and
prompt-cache pricing is the same for both policies. The second is a
sparse sanitized public aggregate from this repository's source runs,
grouped by retention mode, included descriptively to show how
first-token latency and cache hit ratio actually moved under
in_memory versus 24h.
The pairing is the part worth pausing on. Hit ratio alone can read as
reassuring while the retention choice surfaces somewhere else: in this
slice both modes held a high hit ratio (about 0.93 to 0.96), so reading
hit ratio by itself would suggest the retention mode barely mattered.
The first-token latency tail tells the other half of the story —
at cardinality 1 the in_memory series sat near
106,000 ms p95 while the 24h series sat near
9,900 ms, so the retention choice showed up in the latency tail,
not in hit ratio. That is why retention should be read with latency
beside cached-token share — and why it is a request policy and a
governance choice, not just a performance knob. The two retention
modes, their lifetimes, the in_memory default, the equal
pricing, and the in-region condition for extended retention are what
Microsoft Learn documents; the public latency-beside-hit-ratio slice is
source-run evidence this repository defends, not a universal latency
curve. The charts below make that pairing explicit.
Question
When the operation expects cache reuse later, does the request actually ask for that window?
Evidence
Microsoft Learn defines the retention modes; this repo adds sparse public latency and hit-rate evidence.
Decision
Make retention explicit, keep the prefix stable, and read latency beside cached-token share.
Official behavior · two retention modes
Automatic caching is not the same as explicit retention
Microsoft Learn describes two prompt-cache retention policies:
in_memory and 24h. In-memory cache entries are
typically cleared within 5 to 10 minutes of inactivity and are always
removed within one hour of last use. Extended retention can keep cached
prefixes active for longer, up to a maximum of 24 hours.
Default can be short
For gpt-5.4 and older models, omitted retention means in_memory.
Longer reuse is explicit
If the operation expects later reuse, set prompt_cache_retention to 24h where supported.
Price is not the differentiator
Microsoft Learn states prompt-cache pricing is the same for both retention policies.
Observed evidence · sparse public slice
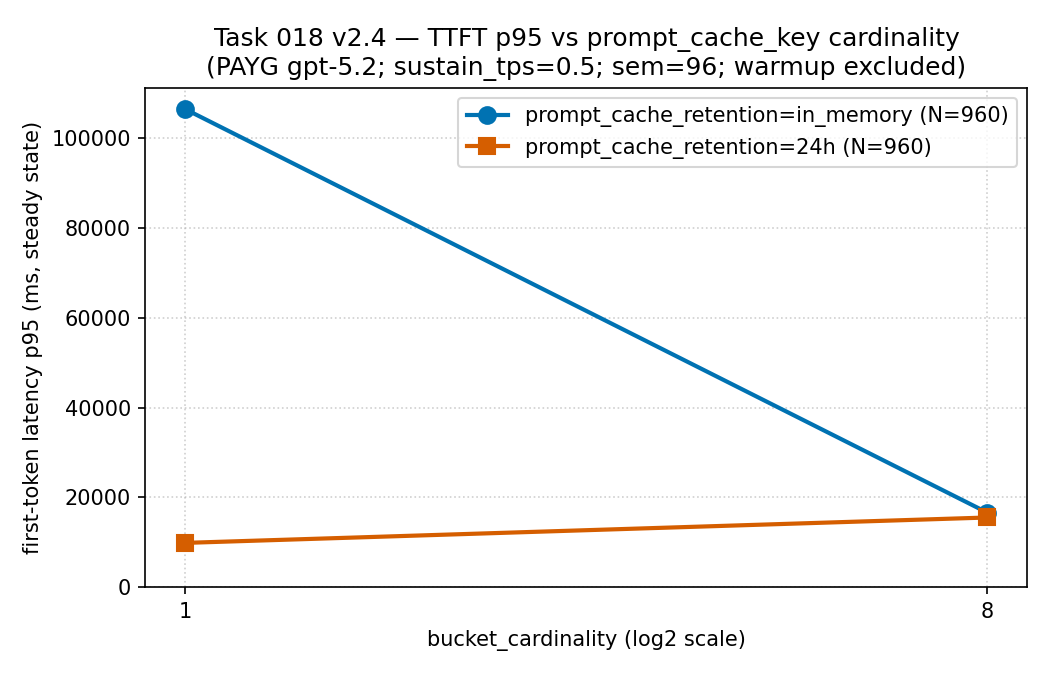
Latency made the retention choice visible
in_memory with 24h for the same cardinality.

in_memory and 24h,
N = 960 records each; a two-series line chart, not a
frequency histogram. How to read it: at
cardinality 1 the in_memory series sat at about
106,000 ms p95 while the 24h series sat at about
9,900 ms — in this cell the retention choice was visible in
the latency tail — and the two series moved closer once traffic
was spread across 8 buckets. Evidence boundary: one
sparse sanitized public aggregate on pay-as-you-go gpt-5.2 (not PTU);
source-run evidence, not a universal latency rule.
Source:
results/cache-key-bucketing/ttft_p95_vs_cardinality.csv
(source CSV).
in_memory and
24h series, N = 960 each.
How to read it: both series stayed high in this slice
(about 0.93–0.96), with the 24h series slightly
higher at cardinality 1; the larger retention difference here
showed up in the latency panel above, not in hit ratio — which is
why retention should be read with latency beside cached-token share.
Evidence boundary: the same sparse sanitized public
aggregate on pay-as-you-go gpt-5.2 (not PTU); descriptive, not a
universal cache-hit rule. Source:
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv
(source CSV).
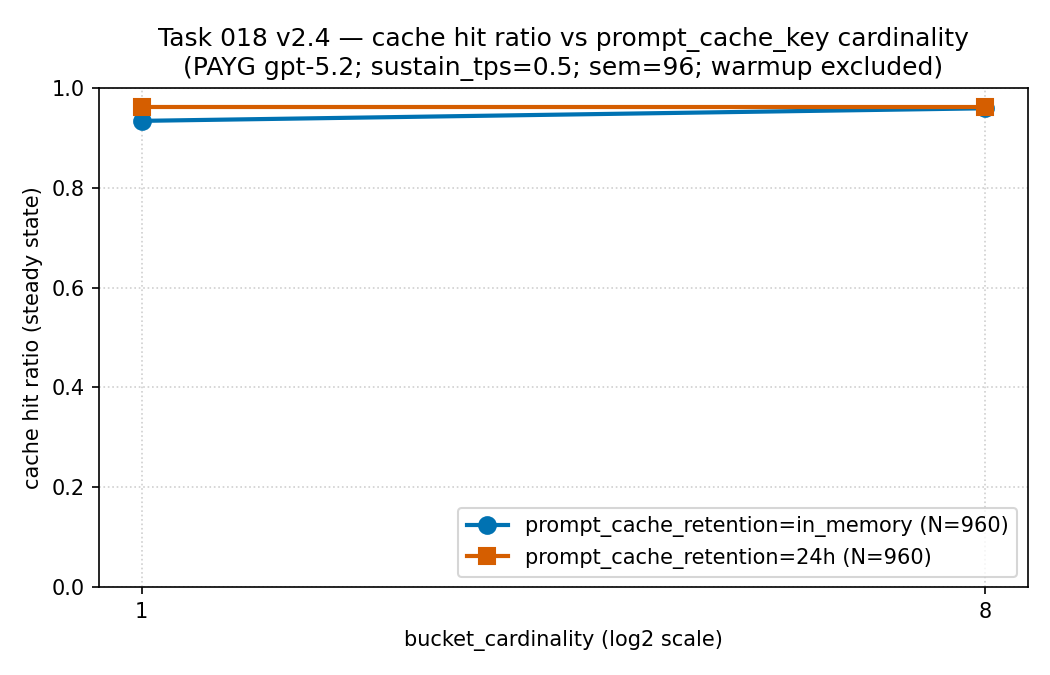
| Retention | Cardinality | Hit ratio | TTFT p95 | Steady records |
|---|---|---|---|---|
| in-memory | 1 | 0.9334 | 106,389.96 ms | 388 |
| 24h | 1 | 0.9612 | 9,899.74 ms | 390 |
| in-memory | 8 | 0.9586 | 16,623.66 ms | 389 |
| 24h | 8 | 0.9612 | 15,549.08 ms | 389 |
What this does and does not prove
In this public slice, the cardinality-1 cell made retention visible in first-token latency. That is source-run evidence, not a universal rule. The durable lesson is simpler: read retention mode, hit ratio, and latency together.
Operating policy · fail closed on ambiguity
If retention matters, make the choice observable
The public repo includes a small retention-policy helper that rejects an
omitted value on models whose documented default is in_memory.
That sounds strict, but it prevents the common failure mode: the design
assumes a longer cache window while the request body silently takes the
short default.
Good
prompt_cache_retention="24h" when the workload depends on later reuse.
Also good
prompt_cache_retention="in_memory" when the workload only needs short reuse and says so explicitly.
Risky
Leaving the value absent while the operating runbook assumes a longer window.
Governance note · retention is not just latency
Longer retention also needs a governance check
Microsoft Learn states that in-memory prompt caching is compatible with all data-residency regions. For extended retention, it says cached data stays in-region only for Regional Standard or Regional Provisioned modes. That makes retention a governance decision as well as a performance decision.
Longer retention is therefore a governance decision as much as a performance one: confirm that the serving mode keeps cached data in-region before relying on the extended window, instead of leaving the choice to a default.
Sources and evidence boundary
Tier 1 — service contract (Microsoft Learn). The two
retention policies, the in-memory clear-and-removal windows, the 24-hour
extended-retention ceiling, the gpt-5.4-and-older
in_memory default, the equal pricing across both policies,
and the data-residency behavior are documented here.
- [1] Prompt caching with Azure OpenAI — documents the
in_memoryand24hretention policies, the in-memory clear within 5 to 10 minutes of inactivity and removal within one hour of last use, the extended-retention ceiling of 24 hours, the default ofin_memoryforgpt-5.4and older models, equal prompt-cache pricing across both retention policies, and the data-residency rule that extended retention keeps cached data in-region only for Regional Standard or Regional Provisioned deployment types. accessed 2026-06-04: https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/prompt-caching; https://web.archive.org/web/20260604174202/https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/prompt-caching.
Tier 2 — operational inference (this repository). The
retention-policy helper that fails closed on an omitted value for
in_memory-default models, and the sparse public hit-ratio and
first-token-latency slice, are repository operational inference and
source-run evidence, not Learn specifications.
- [2] this repository,
docs/12-prompt-cache-key-policy.md— the prompt-cache-key and retention runbook: §4 derives thein_memorydefault table from the documented per-model defaults and prescribes makingprompt_cache_retentionexplicit. source. - [3] this repository,
batch-runner/batch_runner/cache/retention_policy.py— theensure_explicithelper that raises on an omitted value for a model whose documented default isin_memory; operational inference, not a Learn specification. source. - [4] this repository,
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv— the sparse public aggregate slice behind the retention hit-ratio and first-token-latency table; source-run evidence, not a universal latency rule. source.
What this topic does and does not prove. It documents the
prompt-cache retention contract as Microsoft Learn states it on the access
date — the in_memory and 24h policies, the
in-memory clear-and-removal windows, the 24-hour extended ceiling, the
gpt-5.4-and-older in_memory default, equal
pricing across both policies, and the in-region residency condition for
extended retention — plus a repository rule of thumb: make
prompt_cache_retention explicit and fail closed when it is
omitted on an in_memory-default model. The single public slice
showed retention becoming visible in first-token latency at cardinality 1;
that is source-run evidence, not proof of a universal latency curve across
every model, region, or traffic shape.
The practical rule
The practical rule: when cache reuse must survive a short idle
window on a model that can fall back to in_memory, set
prompt_cache_retention explicitly instead of trusting the
default, keep the cacheable prefix stable, and read first-token latency
beside cached-token share to confirm the window you asked for is the
window you got.
The next essay turns from a single request's cache policy to what changes when a whole GPT-4o workload is re-sized for GPT-5.x on PTU.
When GPT-4o traffic moves to GPT-5.x on PTU, what actually changes in the capacity math?