संचालन-लेख · prompt cache रिटेंशन
रिटेंशन मान्यता नहीं, request की नीति है
समर्थित मॉडल eligible prefix को डिफ़ॉल्ट रूप से cache कर लेते हैं, इसलिए prompt
caching अक्सर अपने-आप चलती हुई लगती है। तब सहज रूप से उसी पर भरोसा हो जाता है —
workload किसी idle gap के बाद, shift boundary पार करके, batch pause के बाद, या
बाद की customer turn में वही shared prefix फिर इस्तेमाल करता है, और request body
में बस prompt_cache_retention नहीं भेजा जाता, यह मानकर कि वह window
अभी भी बनी होगी। लेकिन "डिफ़ॉल्ट रूप से cache होता है" और "operation जितनी देर
मानकर चल रहा है उतनी देर retained रहता है" एक ही बात नहीं हैं। अगर request
retention नहीं माँगती, तो operation शायद ऐसी cache window पर निर्भर हो जो उसने
कभी माँगी ही नहीं। इसलिए असली सवाल "cache on है?" नहीं, बल्कि "जिस reuse window
पर यह workload निर्भर है, क्या request ने उसे साफ़ तौर पर माँगा है?" है।
in_memory
default बताता है जो कुछ ही मिनटों में साफ़ हो सकता है, और एक explicit
24h window भी। यह one-pager एक ही बात पर ज़ोर देता है — अगर बाद का
reuse अहम है, तो retention को explicit रखें — और साथ ही सीमा भी साफ़ करता है।
retention modes आधिकारिक spec हैं, जबकि उनके साथ दिखाया गया first-token latency
shape PAYG पर मापा गया sanitized public aggregate है, जिसे यहाँ सिर्फ़
वर्णनात्मक रूप में रखा गया है।
cache रिटेंशन का एक-पृष्ठ सार SVG खोलें।

मान लेने के बजाय window क्यों सेट करें
"डिफ़ॉल्ट काफ़ी है" वाली सहज प्रतिक्रिया यह मान लेती है कि cache window उतनी देर
बनी रहेगी, जितना gap workload दो reuse के बीच छोड़ता है। इसे मान लेने से पहले दो
बातों को साथ रखकर देखना चाहिए। पहली बात Microsoft Learn की documented behavior
है: retention policies दो हैं — in_memory और 24h।
in-memory entries आमतौर पर 5–10 मिनट की inactivity के भीतर साफ़ हो जाती हैं और
last use के 1 घंटे के भीतर हमेशा हटा दी जाती हैं, जबकि extended retention
cacheable prefix को अधिकतम 24 घंटे तक routable रख सकती है। gpt-5.4
और उससे पुराने मॉडलों में value छोड़ने का मतलब in_memory है, और
prompt cache की pricing दोनों policies में एक-सी है। दूसरी बात इस repository के
source runs से लिया गया एक sparse sanitized public aggregate है, जिसे retention
mode के हिसाब से group किया गया है और जो वर्णनात्मक रूप से दिखाता है कि
in_memory और 24h में first-token latency और cache hit
ratio ने व्यवहार में कैसे बदलाव दिखाए।
असली बात इन दोनों को साथ पढ़ने में है। सिर्फ़ hit ratio देखकर बात आश्वस्त करने
वाली लग सकती है, जबकि retention choice का असर कहीं और सामने आता है। मापे गए इस
हिस्से में दोनों modes का hit ratio ऊँचा रहा (क़रीब 0.93–0.96), इसलिए अगर आप
सिर्फ़ वही देखें तो लगेगा कि retention mode से ज़्यादा फ़र्क़ नहीं पड़ा। लेकिन
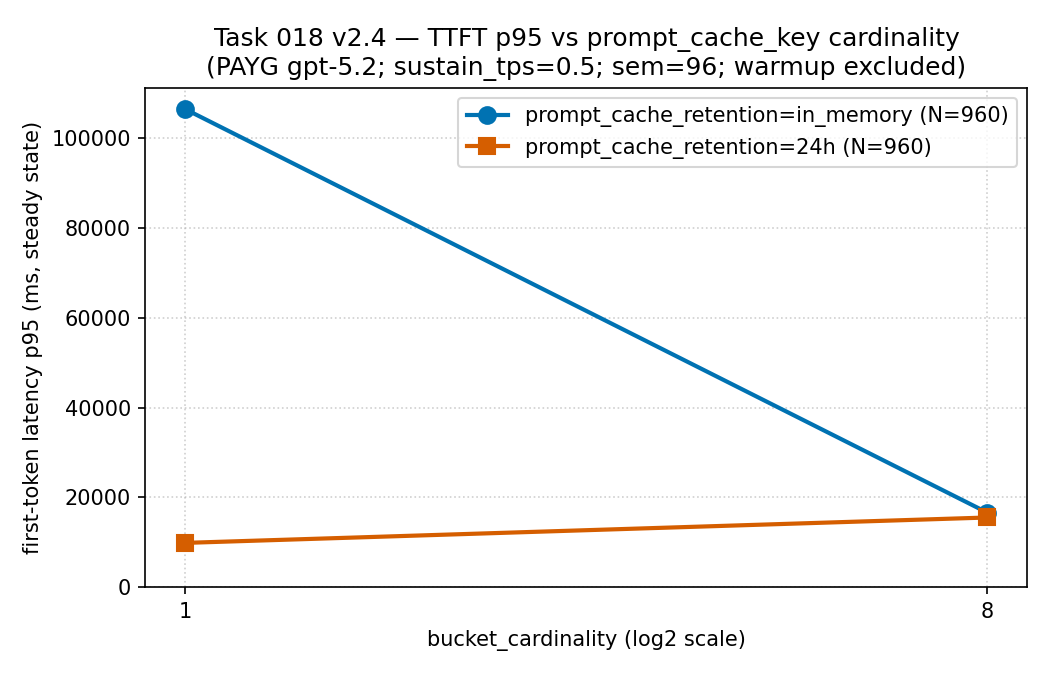
first-token latency tail कहानी का दूसरा हिस्सा दिखाती है — cardinality 1 पर
in_memory series क़रीब 106,000 ms p95 पर थी, जबकि
24h series क़रीब 9,900 ms पर। यानी यहाँ retention choice hit ratio
में नहीं, latency tail में दिखी। इसी वजह से retention को cached-token share के
साथ latency रखकर पढ़ना चाहिए — यह सिर्फ़ performance setting नहीं, request policy
और governance choice भी है। दो retention modes, उनकी lifetime,
in_memory default, एक-सी pricing, और extended retention की
in-region शर्त Microsoft Learn documented behavior के रूप में देता है। latency और
hit ratio को साथ रखकर दिखाया गया यह public evidence इस repository का source-run
सबूत है, कोई universal latency curve नहीं। नीचे के charts वही pairing साफ़ करते
हैं।
सवाल
जहाँ operation बाद में cache reuse की उम्मीद करता है, क्या request सचमुच वही window माँग रही है?
सबूत
Microsoft Learn retention modes को define करता है, और यह repository sparse public latency और hit-ratio evidence जोड़ती है।
निर्णय
retention को explicit रखें, prefix stable रखें, और latency को cached-token share के साथ पढ़ें।
आधिकारिक व्यवहार · दो retention modes
Automatic caching, explicit retention के बराबर नहीं
Microsoft Learn दो prompt cache retention policies बताता है —
in_memory और 24h। in-memory cache entries आमतौर पर
5–10 मिनट की inactivity के भीतर साफ़ हो जाती हैं और last use के 1 घंटे के भीतर
हमेशा हटा दी जाती हैं। extended retention cacheable prefix को अधिकतम 24 घंटे तक
active रख सकती है।
Default window छोटी हो सकती है
gpt-5.4 और उससे पुराने मॉडलों में retention छोड़ने का मतलब in_memory है।
Longer reuse को explicit रखें
अगर बाद का reuse अपेक्षित है, तो जहाँ support हो वहाँ prompt_cache_retention को 24h पर सेट करें।
Price यहाँ फ़र्क़ नहीं बनाती
Microsoft Learn के अनुसार prompt cache pricing दोनों retention policies में एक-सी है।
देखा गया सबूत · मापा गया public हिस्सा
Retention का असर latency में साफ़ दिखा
in_memory और 24h की
तुलना करता है।

in_memory और 24h, हर एक N = 960 records।
यह two-series line chart है, frequency histogram नहीं। इसे कैसे
पढ़ें: cardinality 1 पर in_memory series क़रीब
106,000 ms p95 पर थी और 24h series क़रीब 9,900 ms पर —
इस configuration में retention का असर latency tail में दिखा — और traffic 8
buckets में बँटते ही दोनों series एक-दूसरे के क़रीब आ गईं।
सबूत-सीमा: PAYG gpt-5.2 पर एक sparse sanitized public
aggregate (PTU नहीं)। source-run evidence, universal latency rule नहीं।
स्रोत:
results/cache-key-bucketing/ttft_p95_vs_cardinality.csv
(स्रोत CSV)।
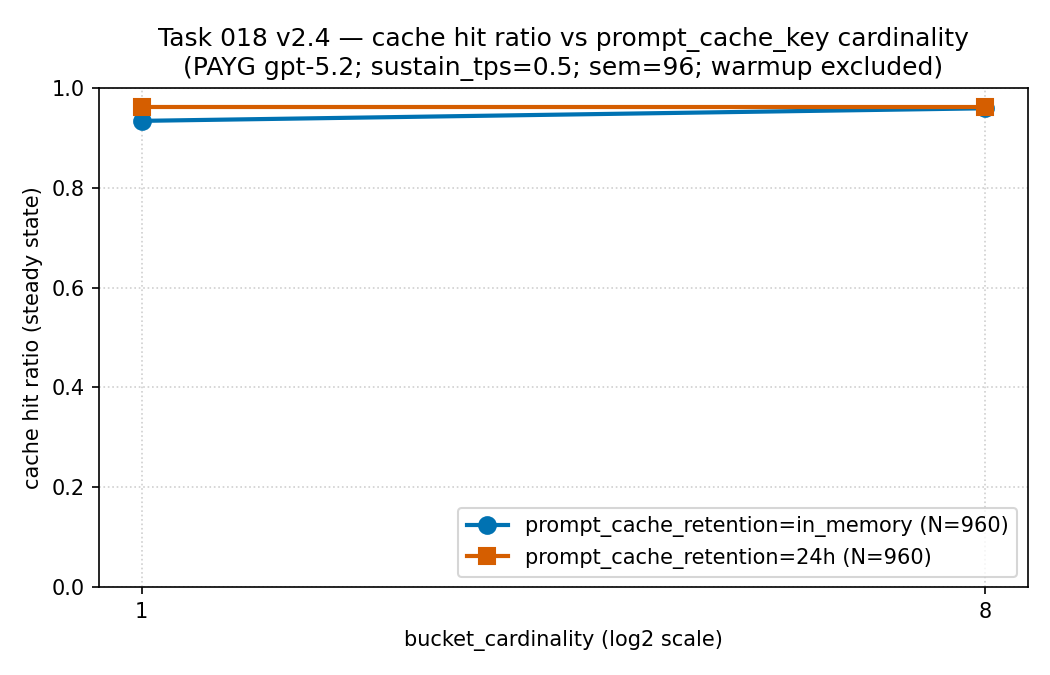
in_memory और 24h
series, हर एक N = 960। इसे कैसे पढ़ें: मापे गए इस
हिस्से में दोनों series ऊँची रहीं (क़रीब 0.93–0.96), और cardinality 1 पर
24h series थोड़ी ऊँची थी। यहाँ retention का बड़ा फ़र्क़ hit ratio
में नहीं, ऊपर वाले latency panel में दिखा — इसलिए retention को cached-token
share के साथ latency रखकर पढ़ना चाहिए। सबूत-सीमा: PAYG gpt-5.2
पर वही sparse sanitized public aggregate (PTU नहीं)। यह वर्णनात्मक है,
universal cache-hit rule नहीं। स्रोत:
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv
(स्रोत CSV)।
| Retention | Cardinality | Hit ratio | TTFT p95 | Steady records |
|---|---|---|---|---|
| in-memory | 1 | 0.9334 | 106,389.96 ms | 388 |
| 24h | 1 | 0.9612 | 9,899.74 ms | 390 |
| in-memory | 8 | 0.9586 | 16,623.66 ms | 389 |
| 24h | 8 | 0.9612 | 15,549.08 ms | 389 |
यह क्या दिखाता है, और क्या नहीं
मापे गए इस public हिस्से में cardinality 1 वाले configuration ने first-token latency में retention का असर साफ़ दिखाया। यह source-run evidence है, universal rule नहीं। टिकाऊ सबक़ इससे भी सरल है — retention mode, hit ratio, और latency को साथ पढ़ें।
संचालन नीति · अस्पष्टता हो तो fail closed
अगर retention अहम है, तो choice साफ़ दिखनी चाहिए
इस public repository में एक छोटा retention-policy helper है, जो उन मॉडलों पर
omitted value स्वीकार नहीं करता जिनका documented default
in_memory है। यह सख़्त लग सकता है, लेकिन यह एक आम failure mode
रोकता है: design लंबी cache window मानकर चलता है, जबकि request body चुपचाप
short default ले लेती है।
अच्छा
जब workload बाद के reuse पर निर्भर हो, तब prompt_cache_retention="24h"।
यह भी अच्छा
जब workload को सिर्फ़ short reuse चाहिए और यह बात explicit हो, तब prompt_cache_retention="in_memory"।
जोखिम भरा
जब operations runbook लंबी window मानकर चलता हो, फिर भी value छोड़ देना।
गवर्नेंस टिप्पणी · retention सिर्फ़ latency की बात नहीं
Longer retention के लिए governance check भी ज़रूरी है
Microsoft Learn के अनुसार in-memory prompt caching सभी data-residency regions के साथ compatible है। extended retention के लिए cached data region के भीतर तभी रहता है जब mode Regional Standard या Regional Provisioned हो। इसलिए retention सिर्फ़ performance decision नहीं, governance decision भी है।
इसलिए longer retention पर भरोसा करने से पहले यह पक्का करें कि serving mode cached data को region के भीतर रखता है। इस चुनाव को default पर न छोड़ें।
स्रोत और सबूत की सीमा
Tier 1 — service contract (Microsoft Learn)। दो retention
policies, in-memory clear और removal windows, 24 घंटे की extended ceiling,
gpt-5.4 और उससे पुराने मॉडलों का in_memory default,
दोनों policies में एक-सी pricing, और data residency behavior यहाँ documented
हैं।
- [1] Azure OpenAI के साथ prompt caching — इसमें
in_memoryऔर24hretention policies, 5–10 मिनट की inactivity के भीतर in-memory clear होना और last use के 1 घंटे के भीतर हटना, 24 घंटे की extended ceiling,gpt-5.4और उससे पुराने मॉडलों के लिएin_memorydefault, दोनों policies में एक-सी prompt cache pricing, और यह data-residency rule documented है कि extended retention cached data को region में तभी रखता है जब mode Regional Standard या Regional Provisioned हो। स्रोत: Microsoft Learn दस्तावेज़ (2026-06-04 को देखा गया) · archive।
Tier 2 — operational inference (यह repository)।
in_memory default वाले मॉडलों पर omitted value को fail closed करने
वाला retention-policy helper, और sparse public hit-ratio व first-token latency
evidence, Learn specifications नहीं बल्कि इस repository का operational inference
और source-run evidence हैं।
- [2] यह repository,
docs/12-prompt-cache-key-policy.md— prompt cache-key और retention runbook। §4 documented per-model defaults सेin_memorydefault table निकालता है औरprompt_cache_retentionको explicit रखने की सलाह देता है। स्रोत। - [3] यह repository,
batch-runner/batch_runner/cache/retention_policy.py—ensure_explicithelper, जो documented defaultin_memoryवाले मॉडलों पर omitted value आने पर error उठाता है। यह Learn specification नहीं, operational inference है. स्रोत। - [4] यह repository,
results/cache-key-bucketing/cache_hit_ratio_vs_cardinality.csv— retention hit ratio और first-token latency table के पीछे का sparse public aggregate। यह universal latency rule नहीं, source-run evidence है. स्रोत।
यह विषय क्या साबित करता है, और क्या नहीं। यह उस access date पर
Microsoft Learn के बताए prompt cache retention contract को दर्ज करता है —
in_memory और 24h policies, in-memory clear और removal
windows, 24 घंटे की extended ceiling, gpt-5.4 और उससे पुराने
मॉडलों का in_memory default, दोनों policies में एक-सी pricing, और
extended retention की in-region residency condition — साथ ही यह repository rule
भी: prompt_cache_retention को explicit रखें, और
in_memory-default model पर value छूट जाए तो fail closed करें। एक
public हिस्से ने दिखाया कि cardinality 1 पर retention का असर first-token
latency में दिखने लगा। यह source-run evidence है, हर model, region, या traffic
shape पर universal latency curve का प्रमाण नहीं।
व्यावहारिक नियम
व्यावहारिक नियम: जिन मॉडलों में default वापस in_memory पर
जा सकता है, वहाँ अगर cache reuse को छोटी idle window से आगे भी टिके रहना है, तो
default पर भरोसा न करें। prompt_cache_retention को explicit सेट
करें, cacheable prefix को stable रखें, और यह जाँचने के लिए कि आपने जो window
माँगी थी वही मिली भी है, cached-token share के साथ first-token latency पढ़ें।
अगला लेख एक request की cache policy से आगे बढ़कर देखता है कि पूरा GPT-4o workload PTU पर GPT-5.x के लिए resize करने पर capacity math में क्या बदलता है।
जब GPT-4o ट्रैफ़िक PTU पर GPT-5.x में जाता है, तो capacity math में असल में क्या बदलता है?