संचालन निबंध · PTU recovery और 429 handling
429 सिर्फ़ error नहीं, रिकवरी का संकेत है
ट्रैफ़िक का एक burst PTU capacity को 100% utilization तक पहुँचा देता है, और calls
429 लौटाने लगती हैं। ऐसे में आम तौर पर तीन रास्ते सूझते हैं: capacity खाली दिखने
तक health-check polling loop चलाते रहो, बिना पक्की जानकारी के किसी fixed timer पर
retry करो, या सारा ट्रैफ़िक तुरंत किसी दूसरे target पर भेज दो। इन तीनों के पीछे
एक ही मान्यता है: दोबारा कोशिश कब सुरक्षित होगी, इसका अंदाज़ client को खुद लगाना
पड़ेगा। लेकिन ऐसा नहीं है — 429 जवाब यह बात पहले ही header
retry-after-ms में बता देता है। इसलिए असली operations सवाल “call fail
हुई क्या?” नहीं, बल्कि “अगला फैसला किसके हाथ में है — wait, redirect, या give up?”
है।
retry-after-ms header ही admission contract होता है। उसका
पालन करें, jitter जोड़ें, और दिखी हुई long tail के लिए budget रखें। यह one-pager
यही एक बात कहता है और evidence boundary भी साफ़ करता है — header Microsoft Learn
का contract है, जबकि उसके साथ दिखा short-median, long-tail आकार इस repository के
source runs से लिया गया sanitized public aggregate है, जिसे सिर्फ़ descriptive रूप
में दिखाया गया है।
429 recovery one-pager SVG खोलें।

अंदाज़ लगाने के बजाय header क्यों पढ़ें
इन तीनों शुरुआती प्रतिक्रियाओं के पीछे एक छिपी हुई मान्यता है — client यह जान
ही नहीं सकता कि capacity कब खाली होगी, इसलिए उसे या तो probe करना पड़ेगा, या किसी
fixed interval पर wait करना पड़ेगा, या फिर target छोड़ना पड़ेगा। इसे मान लेने से
पहले दो चीज़ें साथ रखनी चाहिए। पहली, Microsoft Learn क्या document करता है: 100%
utilization पर service तुरंत 429 लौटाती है और retry-after-ms जोड़ती
है — यानी service खुद बताती है कि दोबारा कब कोशिश करनी है। दूसरी, इस repository
के source runs में वास्तव में देखे गए retry-after-ms values का एक
sanitized public aggregate, जिसे descriptive रूप में इसलिए शामिल किया गया है ताकि
दिख सके कि व्यवहार में ये सुझाए गए waits कैसे दिखे। इन दोनों को साथ देखने पर “कब
दोबारा कोशिश करना सुरक्षित है?” यह सवाल client के अंदाज़े से निकलकर service के
दिए हुए value पर आ जाता है।
उस aggregate की shape पर ठहरकर देखना चाहिए। सुझाए गए waits median पर छोटे थे —
overall p50 ≈ 43 ms — इसलिए health-check loop या blind fixed-interval
backoff आम तौर पर service की असल मांग से कहीं ज़्यादा देर wait करते। लेकिन tail
मामूली नहीं थी: waits का एक छोटा हिस्सा 17,000 ms तक खिंचता था (overall p99
≈ 16,921 ms)। यही short-median, long-tail shape operationally सबसे
अहम बात है — header को fixed reset clock नहीं, admission-control signal की तरह
लेना चाहिए। तुरंत 429 मिलना और retry-after-ms contract, यह Microsoft
Learn document करता है। किस point पर wait बंद करके redirect करना चाहिए, इसे एक
latency-budget ceiling से तय करना इस repository का operational inference है। नीचे
दिया source chart उसी distribution को साफ़ दिखाता है।
सवाल
जब PTU capacity “अभी नहीं” कहे, तो client अगला कदम कैसे तय करे?
सबूत
Microsoft Learn के provisioned-throughput और spillover documents, साथ में इस repository का PTU admission-controller operational note।
फ़ैसला
retry का owner एक ही रखें। header का पालन करें, jitter जोड़ें, और redirect तभी करें जब latency policy इसकी मांग करे।
आधिकारिक spec · service क्या कहती है
header ही admission signal है
Microsoft Learn, PTU high-utilization handling को तुरंत 429 लौटाने वाले path के
रूप में बताता है, जिसके साथ retry-after-ms और
retry-after response headers आते हैं। वही production guide यह भी
समझाती है कि इस wait को client-side retry के लिए भी इस्तेमाल किया जा सकता है और
request को किसी दूसरे serving target पर redirect करने के लिए भी।
क्या documented है
retry-after-ms को service द्वारा दिए गए wait value की तरह लें।
यह किसी guessed fixed reset interval से ज़्यादा भरोसेमंद signal है।
क्या documented नहीं है
इस wait value के पीछे का exact formula public नहीं है। client में कोई deterministic reset model hard-code न करें।
Operational inference
अगर header पहले ही बता रहा है कि दोबारा कब कोशिश करनी है, तो health-check polling आम तौर पर उससे कमज़ोर signal देती है और extra traffic के साथ noisier telemetry भी जोड़ती है।
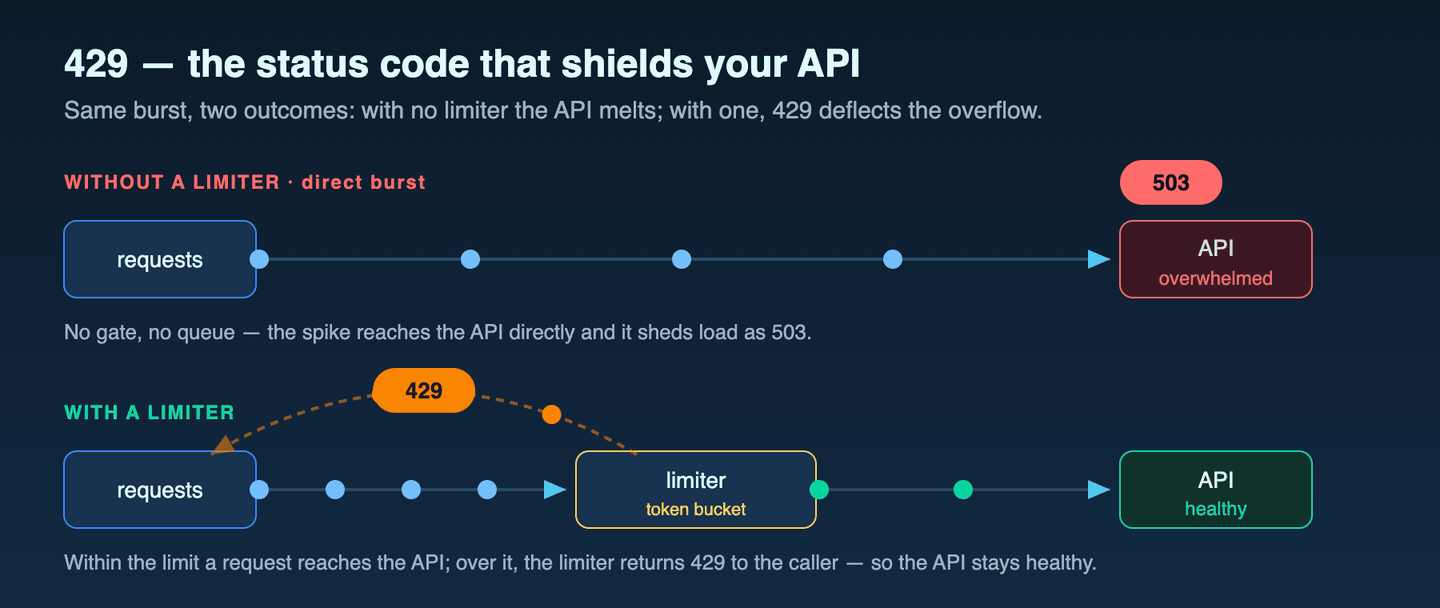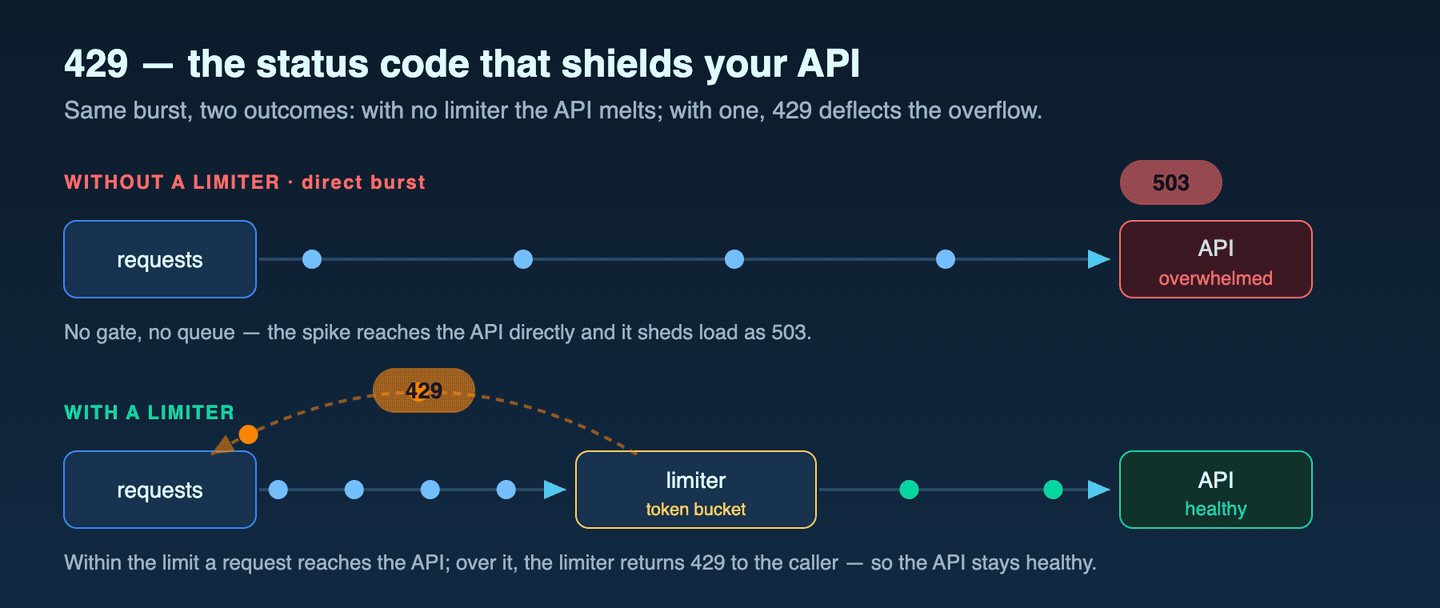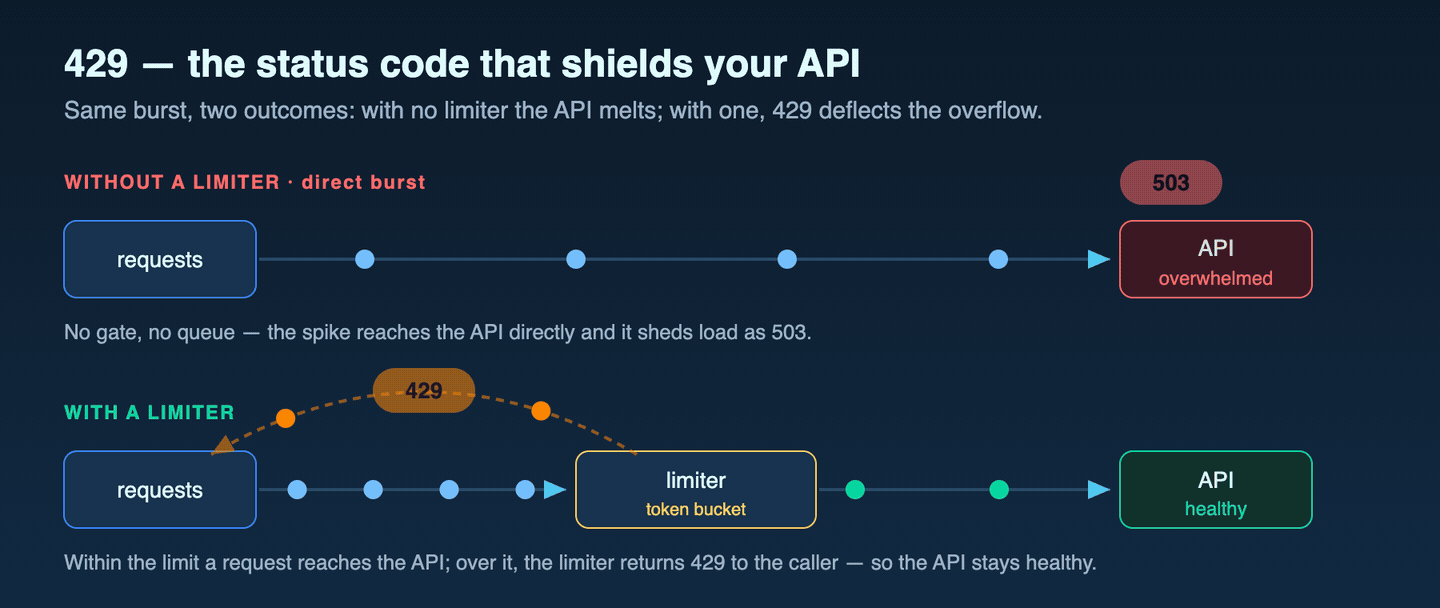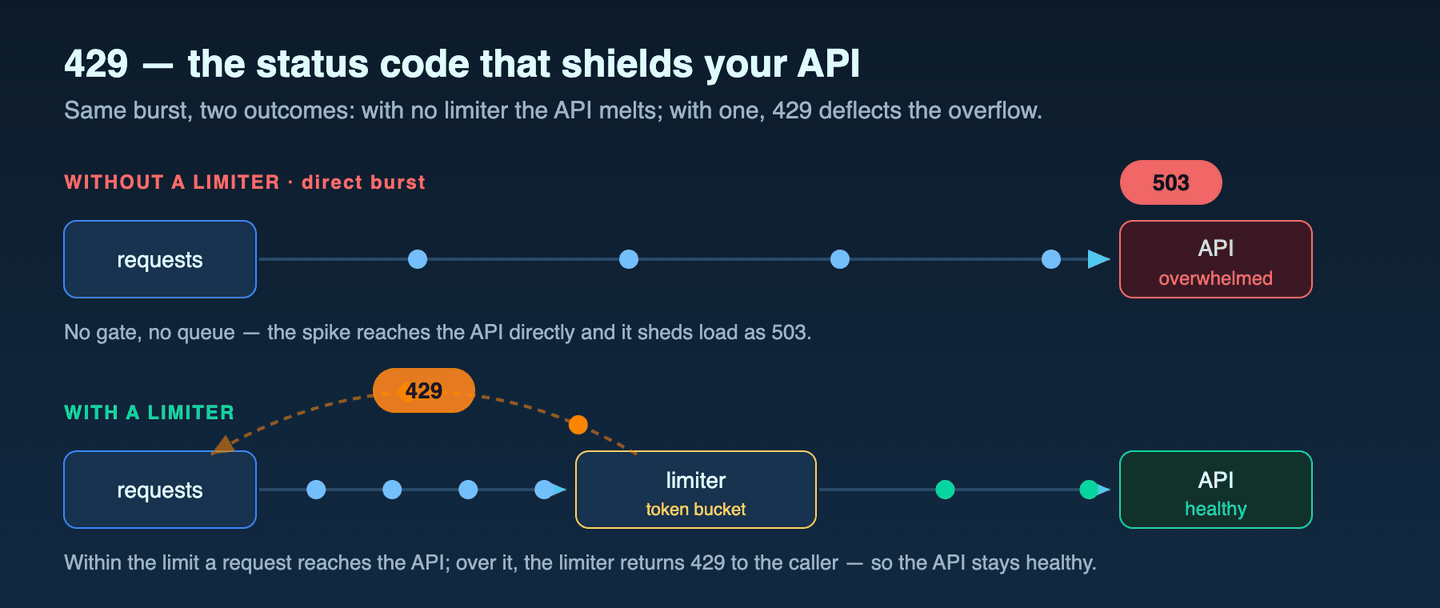
service behavior · wait constant क्यों नहीं है
यह wait admission control है, fixed cooldown नहीं
Microsoft Learn, PTU utilization को leaky-bucket algorithm के एक variation की
तरह document करता है। हर request एक estimated compute cost जोड़ती है — prompt
token count, जिसमें cached tokens घटे होते हैं, और call का
max_tokens जुड़ा होता है — जबकि deployed capacity PTUs की संख्या के
अनुपात में लगातार drain होती रहती है। अगर request उस समय पहुँचे जब utilization
पहले से 100% हो, तो service तुरंत HTTP 429 लौटाती है और
retry-after-ms व retry-after headers जोड़ती है, जो
बताते हैं कि अगली request स्वीकार होने से पहले कितना wait करना है।
क्योंकि यह wait उस पल bucket किस तरह drain हो रही है, उसे reflect करती है, इसलिए यह fixed cooldown नहीं है। यही documented contract client को एक नहीं, दो रास्ते देती है: अगर wait caller के latency budget में fit बैठती है, तो header का पालन करें; अगर wait उस budget से ऊपर जाती है, तो उसे redirect-or-fail condition मानें। एक ही budget ceiling से इन दोनों रास्तों को अलग करना इस repository का operational inference है; तुरंत 429 मिलना और header contract, यही Microsoft Learn document करता है।
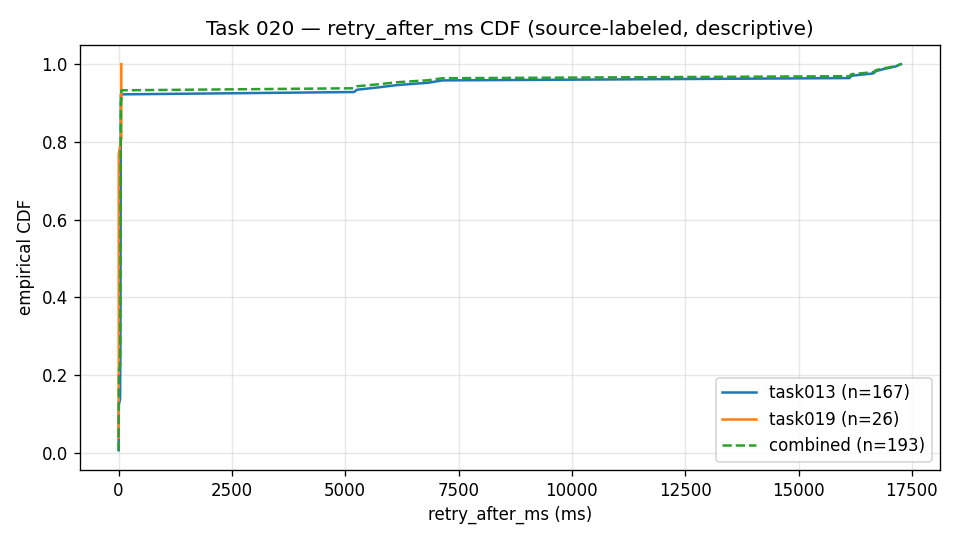
retry-after-ms distribution (descriptive)।
X-axis: response header द्वारा सुझाया गया wait, milliseconds में।
Y-axis: उस wait से कम या बराबर 429 responses का empirical
cumulative share।
Lines: हर source group के लिए एक curve, साथ में combined curve —
burst-shaped source (n = 167), scheduled-shaped source
(n = 26), और combined sample (n = 193); यह empirical
cumulative distribution है, frequency histogram नहीं।
इसे कैसे पढ़ें: हर curve zero के पास लगभग ऊपर तक पहुँच जाती है
— यानी इस sample में ज़्यादातर सुझाए गए waits छोटे थे (overall p50
≈ 43 ms) — और फिर करीब 17,000 ms तक जाती long tail में
flatten हो जाती है, इसलिए waits का एक छोटा हिस्सा बहुत लंबा था (overall p99
≈ 16,921 ms)। यही short-median, long-tail shape बताती है कि नीचे दिया
operating pattern wait को latency budget ceiling तक सीमित रखता है और उसके बाद
redirect या fail करता है। Evidence boundary: यह इस repository के
source runs से लिए गए 429 events का एक sanitized public aggregate है, जिसे
descriptive रूप में दिखाया गया है; यह service-level guarantee, reset model, या
किसी खास तैनाती, region, या future API version की measurement नहीं है।
Source: percentile values इस repository की
results/retry-after-characterization/retry_after_ms_percentiles.csv
से ली गई हैं (source CSV)।
| source group | 429 count | p50 | p90 | p99 | Max |
|---|---|---|---|---|---|
| Overall | 193 | 43 ms | 50.8 ms | 16,921.12 ms | 17,258 ms |
| Burst-shaped source | 167 | 43 ms | 49 ms | 16,983.26 ms | 17,258 ms |
| Scheduled-shaped source | 26 | 3 ms | 60 ms | 60 ms | 60 ms |
Documented (Tier 1)
100% utilization पर service तुरंत retry-after-ms और retry-after के साथ 429 लौटाती है; Learn इस 429 को service error नहीं, traffic-management signal कहता है।
Documented (Tier 1)
Estimate में max_tokens शामिल होता है। इसे वास्तविक generation size के क़रीब रखने से concurrency बढ़ती है। cached tokens पूरी तरह discount हो जाते हैं और utilization में नहीं जुड़ते।
Inferred (Tier 2)
Caller एक ही latency-budget ceiling तय करे और उसके ऊपर wait से redirect पर switch करे — यह इस repository का rule of thumb है, Learn specification नहीं।
operating pattern · retry का owner एक
retry loops को stack मत करें
सुरक्षित pattern जान-बूझकर सीधा है: 429 recovery का owner ठीक एक component को
बनाइए। अगर SDK retry के लिए configured है, तो wait उसी को संभालने दें। अगर
application router recovery संभालता है, तो SDK auto-retry बंद करें और router से
सीधे retry-after-ms parse कराएँ।
retry-after-ms parse
करता है, retry-after पर fallback करता है, safe throttle events
emit करता है, और double-retry ownership को मना करता है।

Sleep path
जब per-call latency से ज़्यादा throughput मायने रखता हो, तब यह path लें। header value के साथ jitter जोड़कर wait करें, फिर दोबारा कोशिश करें।
Redirect path
जब PTU पर बने रहने से ज़्यादा latency मायने रखती हो, तब यह path लें। 429 मिलते ही request को standard target पर route करें।
Give-up path
जब wait और redirect, दोनों policy तोड़ते हों, तब यह path लें। retry storms छिपाने के बजाय controlled response लौटाएँ।
fallback · native या custom
redirect एक policy choice है, panic button नहीं
Microsoft Learn की spillover feature, overage traffic को standard target पर redirect कर सकती है और ऐसे headers भी देती है जो spillover behavior पहचानने में मदद करते हैं। जब platform-supported shape आपकी ज़रूरत से मेल खाती हो, तब यह low-operations path है। custom router तब भी काम का रहता है जब application को PTU target से 429 लौटने से पहले फैसला करना हो, या जब routing policy tenant, region, latency budget, या business priority पर निर्भर करती हो।
Native spillover
जब simple overflow lane काफ़ी हो और extra routing logic, value से ज़्यादा risk जोड़ता हो, तब यह सबसे अच्छा विकल्प है।
Custom router
जब user latency खर्च होने से पहले application policy को तय करना हो कि wait करना है, redirect करना है, या give up करना है, तब यह बेहतर है।
Anti-pattern
SDK retry + router retry + spillover मिलकर attempts को कई गुना बढ़ा सकते हैं। सबसे पहले ownership को consolidate करें।
स्रोत और evidence boundary
Tier 1 — service contract (Microsoft Learn). 429 admission behavior, दोनों retry headers, leaky-bucket utilization model, और SDK की default retry यहीं documented हैं।
- [1] production में provisioned throughput तैनात क्षमता चलाना —
100% utilization पर तुरंत 429,
retry-after-msऔरretry-afterresponse headers, leaky-bucket utilization model, और OpenAI SDK की default 429 retry (max_retries) को define करता है। source: Microsoft Learn दस्तावेज़ (2026-06-04 को access किया गया) · archive। - [2] provisioned capacity के लिए spillover से traffic manage करना —
non-200 overage (जिसमें
429भी शामिल है) कोspilloverDeploymentNameproperty और spillover source बताने वाले x-ms response header की मदद से standard target पर redirect करने वाली spillover behavior को define करता है। source: Microsoft Learn दस्तावेज़ (2026-06-04 को access किया गया) · archive।
Tier 2 — operational inference (यह repository). Rules of thumb — retry का owner एक रखें, header का पालन करें, fleet को de-synchronize करने के लिए jitter जोड़ें, और honored waits कई बार लेने के बाद भी बात साफ़ न हो तभी spillover पर redirect करें — operational हैं, Learn specifications नहीं।
- [3] यह repository,
docs/10-ptu-admission-controller.md— header-driven admission controller note: single retry owner,retry-after-msका पालन, default jitter, और wait ceiling पार होने पर fallback। source। - [4] यह repository,
batch_runner/ptu/admission_controller.py— वह reference implementation जोretry-after-msparse करती है,retry-afterपर fallback करती है, और double-retry ownership को मना करती है। source।
यह विषय क्या साबित करता है, और क्या नहीं। यह वही PTU admission
contract दर्ज करता है जिसे Microsoft Learn access date पर बताता है — 100%
utilization पर तुरंत 429, retry-after-ms और
retry-after headers, और spillover redirect path — और उसके साथ इस
repository के कुछ operational rules of thumb भी रखता है: header का पालन करें,
fleet को de-synchronize करने के लिए jitter जोड़ें, और honored waits कई बार लेने
के बाद भी बात साफ़ न हो तभी spillover target पर redirect करें। यह यह साबित नहीं
करता कि यह contract हर region, model SKU, या future API version में बिल्कुल
एक-जैसा रहेगा, और न ही यह किसी खास तैनाती को load पर measure करता है।
व्यावहारिक नियम
व्यावहारिक नियम: जब PTU target 429 लौटाए, तो retry-after-ms
को admission contract मानें — उसका पालन करें, fleet को de-synchronize करने के लिए
jitter जोड़ें, और honored waits कई बार लेने के बाद भी बात साफ़ न हो तभी spillover
target पर redirect करें।
अगला लेख “कब retry करें” से आगे बढ़कर यह पूछता है कि एक ही prompt बार-बार आने पर असल में फ़ैसला क्या होता है।
जब वही prompt दोहराया जाए, तो cache key असल में क्या तय करती है