Operations essay · PTU recovery and 429 handling
429 is a recovery signal, not just an error
A traffic burst pushes a PTU deployment to 100% utilization and the calls
start coming back as 429. The reflex is to reach for one of three moves:
open a health-check polling loop until capacity looks free, retry on a
blind fixed timer, or immediately route everything to another target. Each
one assumes the client has to guess when it is safe to try again. It does
not — the 429 already carries that answer in a header,
retry-after-ms, so the operating question is not “did the call
fail?” but “who owns the next decision: wait, redirect, or give up?”
retry-after-ms header is the
admission contract: honor it, add jitter, and budget for the observed long tail. The
one-pager carries that single message and marks the evidence boundary —
the header is Microsoft Learn's contract, while the short-median,
long-tail shape beside it is a sanitized public aggregate from this
repository's source runs, shown descriptively.
Open the 429 recovery one-pager SVG.

Why read the header instead of guessing
All three reflexes share one hidden assumption: that the client cannot
know when capacity will free up, so it has to probe, wait a fixed
interval, or leave. Before accepting that, two things are worth putting
side by side. The first is what Microsoft Learn documents: at 100%
utilization the service returns 429 immediately and attaches
retry-after-ms, a service-provided wait value for when to
try again. The second is a sanitized public
aggregate of the retry-after-ms values actually observed
across this repository's source runs, included descriptively to show what
those advised waits looked like in practice. Together they turn “when is
it safe to try again?” from a client-side guess into a value the service
hands back.
The shape of that aggregate is the part worth pausing on. The advised
waits were short at the median — overall p50 ≈ 43 ms
— so a health-check loop or a blind fixed-interval backoff would
usually wait far longer than the service actually asked for. But the tail
was not negligible: a small share of waits stretched toward
17,000 ms (overall p99 ≈ 16,921 ms). That short-median,
long-tail shape is the operationally important fact — the header
should be treated as an admission-control signal, not a fixed reset clock.
The immediate 429 and the retry-after-ms contract are what
Microsoft Learn documents; that a single latency-budget ceiling should
decide when to stop waiting and redirect is operational inference this
repository defends. The source chart below makes that distribution
explicit.
Question
When PTU capacity says “not now,” how should the client decide the next move?
Evidence
Microsoft Learn provisioned-throughput and spillover documentation, plus this repository's PTU admission-controller operational note.
Decision
Use one retry owner. Honor the header, add jitter, and redirect only when latency policy demands it.
Official spec · what the service states
The header is the admission signal
Microsoft Learn describes PTU high-utilization handling as an immediate
429 path with retry-after-ms and retry-after
response headers. The same production guide explains that the wait can
be used either for client-side retry or for redirecting the request to a
different serving target.
What is documented
Treat retry-after-ms as a service-provided wait value.
It is stronger than a guessed fixed reset interval.
What is not documented
The exact formula behind the wait value is not public. Do not encode a deterministic reset model in the client.
Operational inference
If the header already says when to try again, health-check polling is usually a weaker signal plus extra traffic and noisier telemetry.
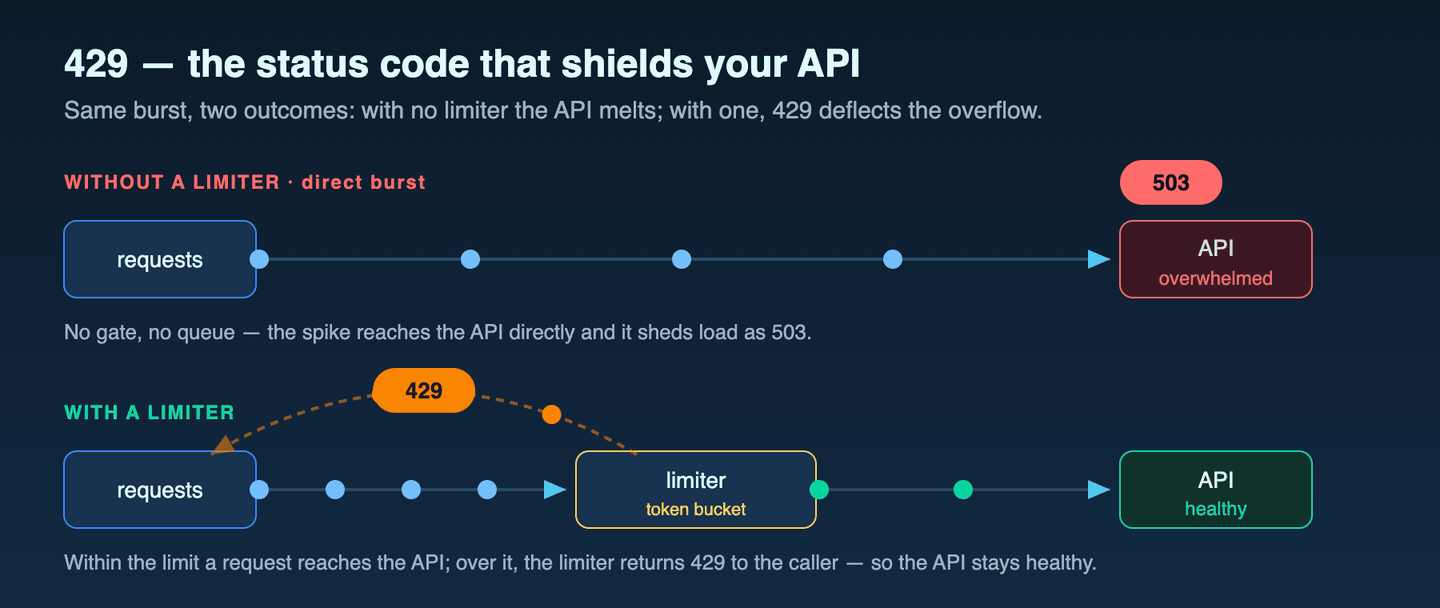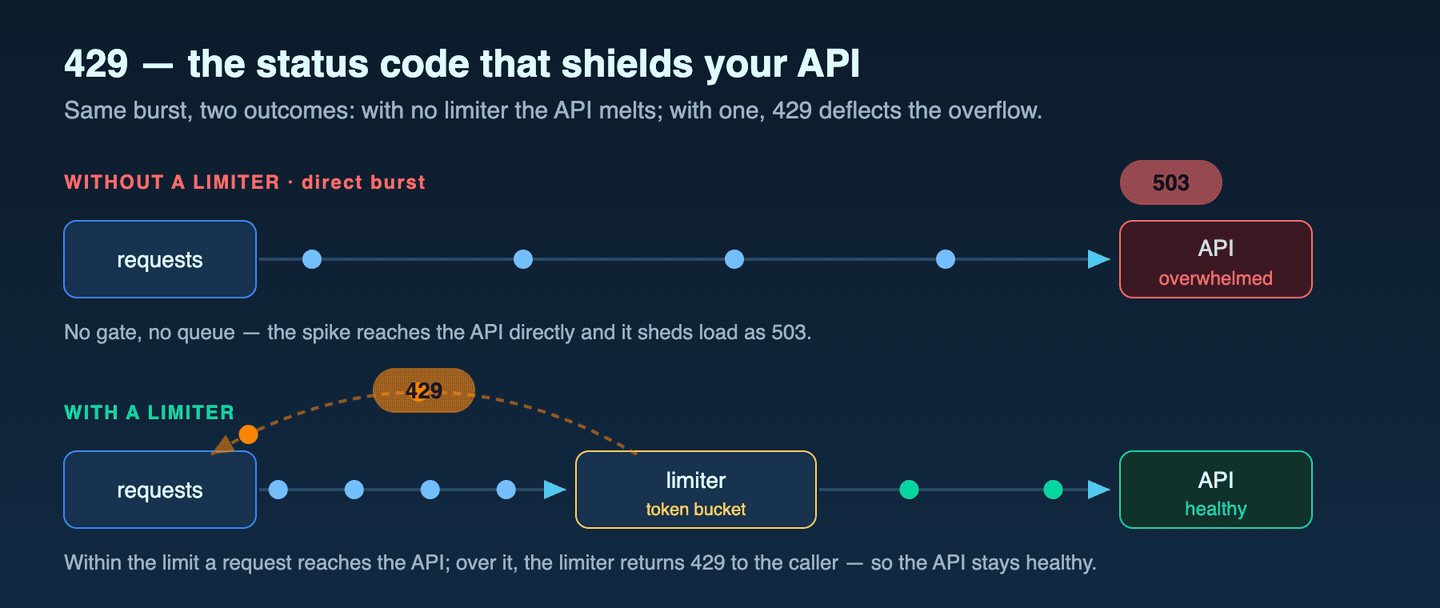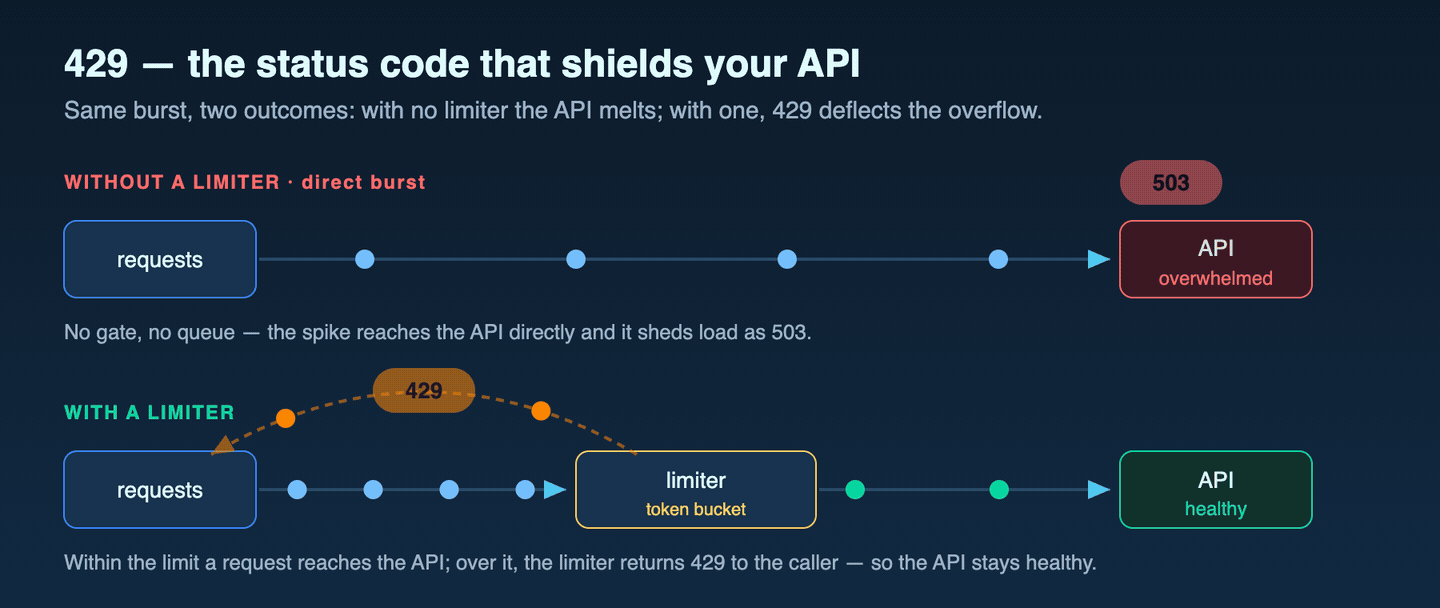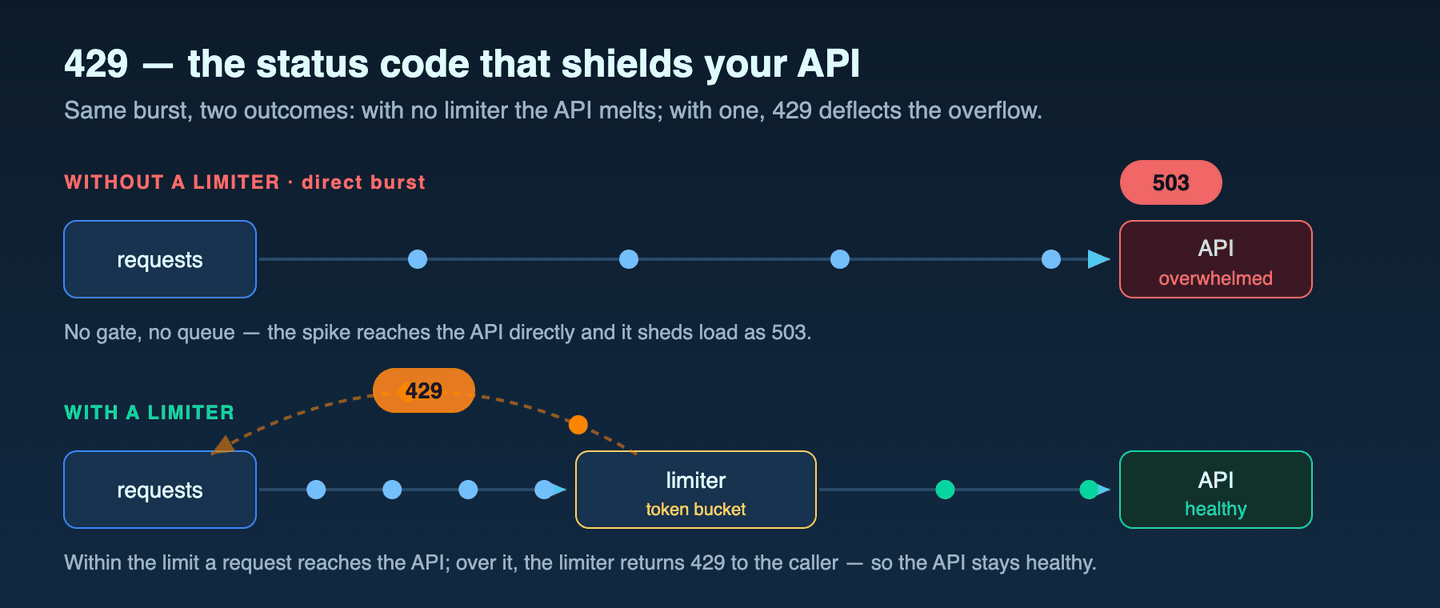
Service behavior · why the wait is not a constant
The wait is admission control, not a fixed cooldown
Microsoft Learn documents PTU utilization as a variation of the leaky
bucket algorithm. Each request adds an estimated compute cost — the
prompt token count, minus cached tokens, plus the call's
max_tokens — while deployed capacity drains continuously in
proportion to the number of PTUs. When a request arrives and utilization
is already at 100%, the service returns HTTP 429 immediately and attaches
retry-after-ms and retry-after headers
indicating how long to wait before the next request is accepted.
Because the wait reflects how the bucket is draining at that instant, it is not a fixed cooldown. The same documented contract therefore supports two client paths rather than one: honor the header when the wait fits the caller's latency budget, and treat any wait that exceeds that budget as a redirect-or-fail condition. That a single budget ceiling should split the two paths is operational inference this repository defends; the immediate 429 and the header contract are what Microsoft Learn documents.
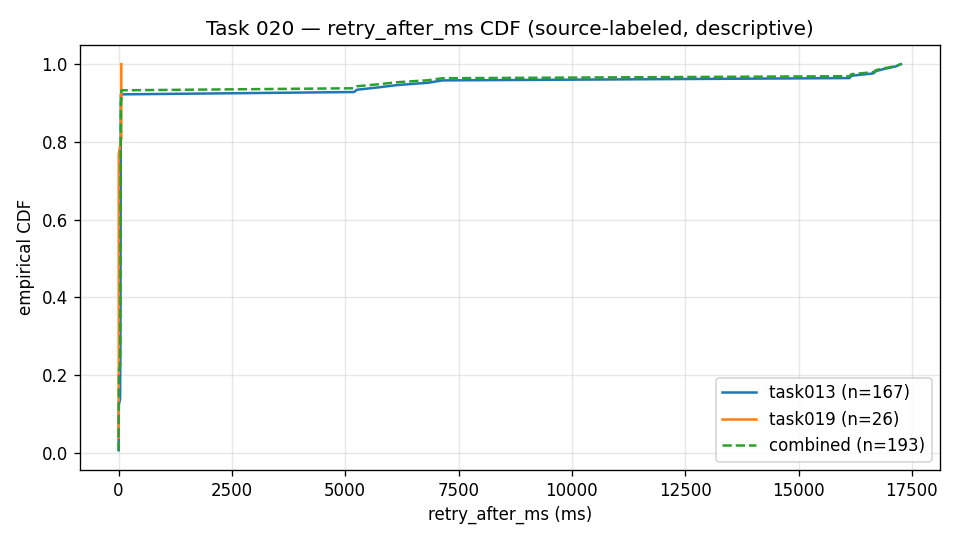
retry-after-ms distribution (descriptive).
X-axis: the wait the response header advised, in
milliseconds. Y-axis: the empirical cumulative share
of 429 responses at or below that wait. Lines: one
curve per source group plus a combined curve — a burst-shaped
source (n = 167), a scheduled-shaped source (n = 26),
and the combined sample (n = 193); this is an empirical
cumulative distribution, not a frequency histogram.
How to read it: each curve rises almost to the top
near zero — in this sample most advised waits were short (overall
p50 ≈ 43 ms) — then flattens into a long tail reaching
about 17,000 ms, so a small share of waits were very long (overall
p99 ≈ 16,921 ms). That short-median, long-tail shape is why
the operating pattern below caps the wait at a latency budget and then
redirects or fails. Evidence boundary: this is one
sanitized public aggregate of 429 events from this repository's source
runs, shown descriptively; it is not a service-level guarantee, a
reset model, or a measurement of any specific deployment, region, or
future API version. Source: percentile values come
from this repository's
results/retry-after-characterization/retry_after_ms_percentiles.csv
(source CSV).
| Source group | 429 count | p50 | p90 | p99 | Max |
|---|---|---|---|---|---|
| Overall | 193 | 43 ms | 50.8 ms | 16,921.12 ms | 17,258 ms |
| Burst-shaped source | 167 | 43 ms | 49 ms | 16,983.26 ms | 17,258 ms |
| Scheduled-shaped source | 26 | 3 ms | 60 ms | 60 ms | 60 ms |
Documented (Tier 1)
At 100% utilization the service returns 429 at once with retry-after-ms and retry-after; Learn calls the 429 a traffic-management signal, not a service error.
Documented (Tier 1)
The estimate uses max_tokens; setting it close to true generation size raises concurrency. Cached tokens receive a full discount and do not add to utilization.
Inferred (Tier 2)
That a caller should set one latency-budget ceiling and switch from waiting to redirecting above it is a repository rule of thumb, not a Learn specification.
Operating pattern · one owner for retry
Do not stack retry loops
The safe pattern is boring on purpose: pick exactly one component to own
429 recovery. If the SDK is configured to retry, let it own the wait. If
an application router owns recovery, disable SDK auto-retry and make the
router parse retry-after-ms directly.
retry-after-ms, falls back to retry-after,
emits safe throttle events, and refuses double-retry ownership.

Sleep path
Use when throughput matters more than per-call latency. Wait the header value plus jitter, then try again.
Redirect path
Use when latency matters more than staying on PTU. Route to a standard target as soon as the 429 arrives.
Give-up path
Use when both wait and redirect violate policy. Return a controlled response rather than hiding retry storms.
Fallback · native or custom
Redirect is a policy choice, not a panic button
Microsoft Learn's spillover feature can redirect overage traffic to a standard target and exposes headers that identify spillover behavior. That is the low-operations path when the platform-supported shape fits. A custom router is still useful when the application must decide before the PTU target returns 429, or when routing policy depends on tenant, region, latency budget, or business priority.
Native spillover
Best when the simple overflow lane fits and extra routing logic would add more risk than value.
Custom router
Best when application policy must choose among wait, redirect, and give-up before user latency is spent.
Anti-pattern
SDK retry plus router retry plus spillover can multiply attempts. Consolidate ownership first.
Sources and evidence boundary
Tier 1 — service contract (Microsoft Learn). The 429 admission behavior, both retry headers, the leaky-bucket utilization model, and the SDK's default retry are documented here.
- [1] Operate provisioned throughput deployments in production — defines the immediate 429 at 100% utilization, the
retry-after-msandretry-afterresponse headers, the leaky-bucket utilization model, and the OpenAI SDK's default 429 retry (max_retries). accessed 2026-06-04: https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/provisioned-get-started; https://web.archive.org/web/20260604161404/https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/provisioned-get-started. - [2] Manage traffic with spillover for provisioned deployments — defines the spillover redirect of non-200 (including
429) overage to a standard deployment via thespilloverDeploymentNameproperty and thex-ms-spillover-from-deploymentresponse header. accessed 2026-06-04: https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/spillover-traffic-management; https://web.archive.org/web/20260604161530/https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/spillover-traffic-management.
Tier 2 — operational inference (this repository). The rules of thumb — one retry owner, honor the header, add jitter to de-synchronize a fleet, and redirect to spillover only after repeated honored waits fail to clear — are operational, not Learn specifications.
- [3] this repository,
docs/10-ptu-admission-controller.md— the header-driven admission controller note: single retry owner, honorretry-after-ms, default jitter, and fallback once the wait exceeds a ceiling. source. - [4] this repository,
batch_runner/ptu/admission_controller.py— the reference implementation that parsesretry-after-ms, falls back toretry-after, and refuses double-retry ownership. source.
What this topic does and does not prove. It documents the
PTU admission contract as Microsoft Learn states it on the access date —
the immediate 429 at 100% utilization, the retry-after-ms and
retry-after headers, and the spillover redirect path — plus a
small set of operational rules of thumb this repository defends: honor the
header, add jitter to de-synchronize a fleet, and redirect to a spillover
deployment only after repeated honored waits fail to clear. It does not
validate that the contract holds identically across every region, model
SKU, or future API version, and it does not measure any specific
deployment under load.
The practical rule
The practical rule: when a PTU deployment returns 429, treat
retry-after-ms as the admission contract — honor it, add
jitter to de-synchronize the fleet, and redirect to a spillover deployment
only after repeated honored waits fail to clear.
The next essay turns from when to retry to what a repeated prompt actually decides.
When the same prompt repeats, what does the cache key actually decide?